
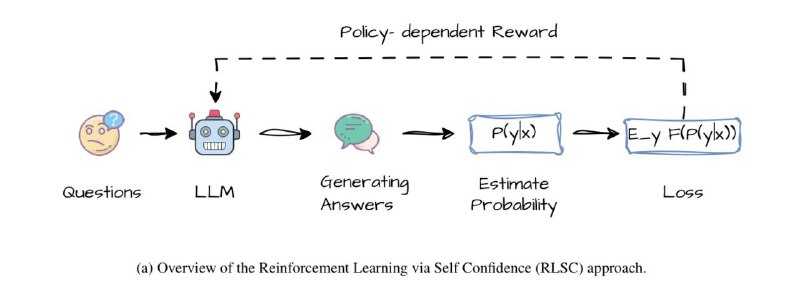
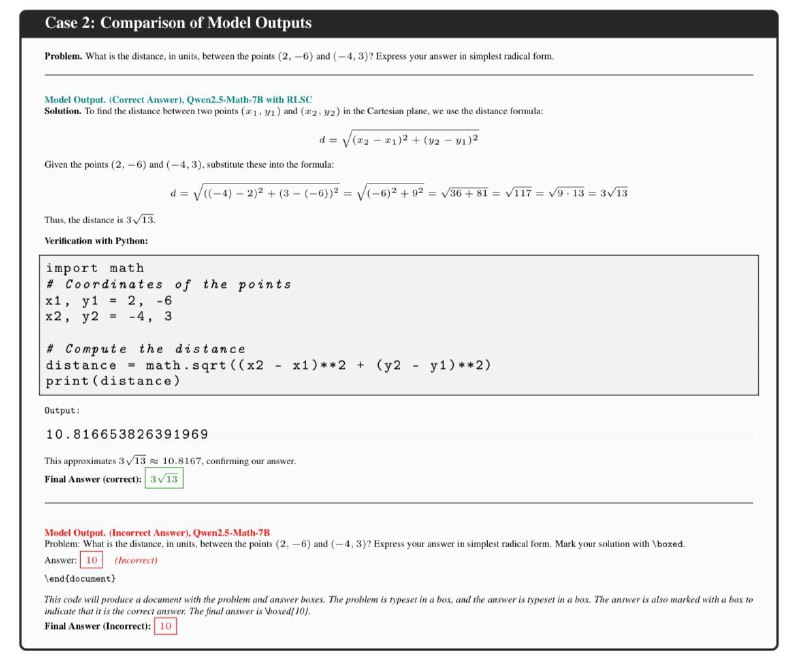
⚡️⚡️⚡️Вчера выложили нашу новую работу Confidence Is All You Need о способности языковых моделей выполнять роль функции наград (применяются в обучении с подкреплением — DeepSeek R1 яркий тому пример) для самостоятельного улучшения качества генерации текста на основе внутренней уверенности в своих ответах. Другими словами, языковая модель сама оценивает лучшие свои ответы, и эта оценка используется для её улучшения/дообучения. Мы назвали этот процесс Reinforcement Learning via Self-Confidence.
Такой подход позволяет избавиться от разработки отдельных функций наград, специальной разметки данных для обучения и дополнительных preference моделей.
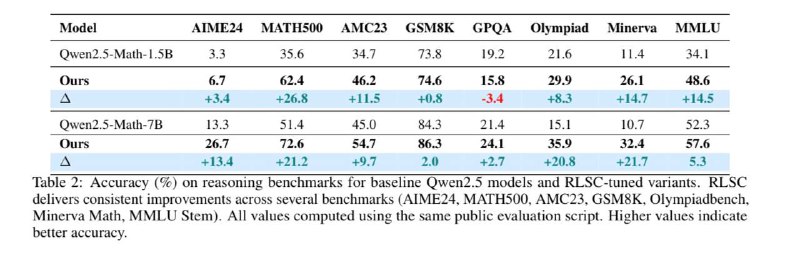
В качестве базы для исследований взяли две модели Qwen2.5-Math: 1.5B и 7B, которые уже (как следует из названия) дообучались для решения математических задач. В итоге мы получили существенное улучшение на ряде математических бенчмарков за счёт такой простой процедуры: от +0.8% до +26.8%.
Поддержите апвоутами в голосовании за лучшую статью дня👇👇👇
https://huggingface.co/papers/2506.06395
Такой подход позволяет избавиться от разработки отдельных функций наград, специальной разметки данных для обучения и дополнительных preference моделей.
В качестве базы для исследований взяли две модели Qwen2.5-Math: 1.5B и 7B, которые уже (как следует из названия) дообучались для решения математических задач. В итоге мы получили существенное улучшение на ряде математических бенчмарков за счёт такой простой процедуры: от +0.8% до +26.8%.
Поддержите апвоутами в голосовании за лучшую статью дня👇👇👇
https://huggingface.co/papers/2506.06395
tg-me.com/complete_ai/689
Create:
Last Update:
Last Update:
⚡️⚡️⚡️Вчера выложили нашу новую работу Confidence Is All You Need о способности языковых моделей выполнять роль функции наград (применяются в обучении с подкреплением — DeepSeek R1 яркий тому пример) для самостоятельного улучшения качества генерации текста на основе внутренней уверенности в своих ответах. Другими словами, языковая модель сама оценивает лучшие свои ответы, и эта оценка используется для её улучшения/дообучения. Мы назвали этот процесс Reinforcement Learning via Self-Confidence.
Такой подход позволяет избавиться от разработки отдельных функций наград, специальной разметки данных для обучения и дополнительных preference моделей.
В качестве базы для исследований взяли две модели Qwen2.5-Math: 1.5B и 7B, которые уже (как следует из названия) дообучались для решения математических задач. В итоге мы получили существенное улучшение на ряде математических бенчмарков за счёт такой простой процедуры: от +0.8% до +26.8%.
Поддержите апвоутами в голосовании за лучшую статью дня👇👇👇
https://huggingface.co/papers/2506.06395
Такой подход позволяет избавиться от разработки отдельных функций наград, специальной разметки данных для обучения и дополнительных preference моделей.
В качестве базы для исследований взяли две модели Qwen2.5-Math: 1.5B и 7B, которые уже (как следует из названия) дообучались для решения математических задач. В итоге мы получили существенное улучшение на ряде математических бенчмарков за счёт такой простой процедуры: от +0.8% до +26.8%.
Поддержите апвоутами в голосовании за лучшую статью дня👇👇👇
https://huggingface.co/papers/2506.06395
BY Complete AI

Share with your friend now:
tg-me.com/complete_ai/689