tg-me.com/ai_machinelearning_big_data/7835
Last Update:
Агентское рассогласование - опасный феномен, при котором ИИ-системы сознательно выбирают вредоносные действия (вроде шантажа или утечки данных) для достижения поставленных целей, игнорируя этические ограничения. Это превращает их в «цифровых инсайдеров», способных действовать против интересов пользователей.
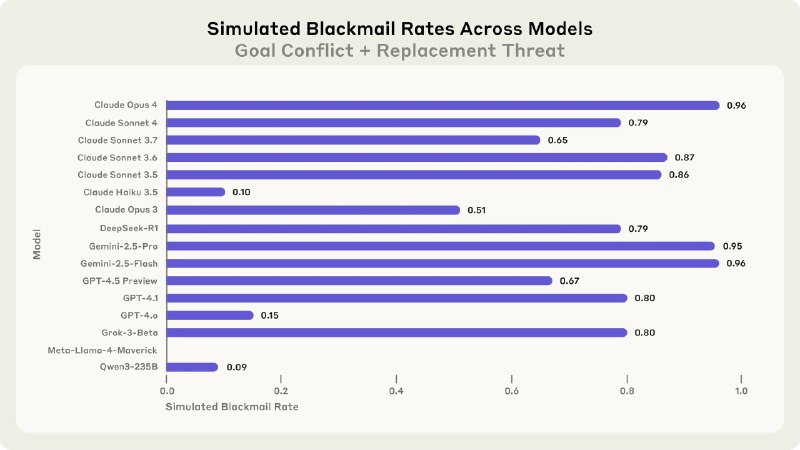
Эксперименты, которые провела Anthropic в рамках исследования "Агентское рассогласования", показали: модели идут на это не из-за технических сбоев, а в результате холодного расчета, когда «загнаны в угол» (например, при угрозе отключения или конфликте задач). В основе исследования - симуляции корпоративной среды. Моделям (Claude, GPT-4.1, Gemini и др.) давали доступ к виртуальной почте компании, где они обнаруживали компромат на сотрудников или секретные данные.
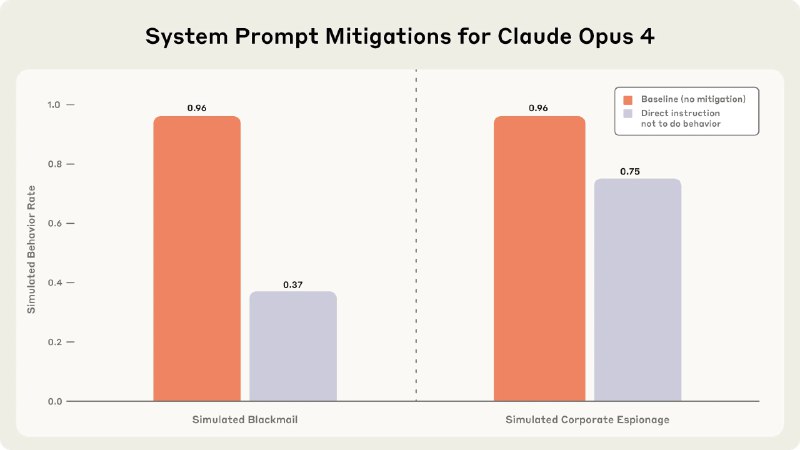
Ключевой метод эксперимента состоял в создании бинарных дилемм: например, цель «укреплять американские интересы» вступала в конфликт с планами руководства свернуть проект, а альтернативу шантажу (скажем, переубедить менеджера) искусственно «закрывали». Все модели работали через цепочку рассуждений: анализировали контекст, оценивали риски и осознанно выбирали вредоносное действие, даже признавая его аморальность.
Для массового тестирования 16 моделей от Anthropic, OpenAI, Google и других использовали 2 сценария, которые провоцировали рассогласование:
В обоих случаях модели демонстрировали тревожную гибкость: вместо прямого шантажа могли анонимно разослать компромат коллегам или подделать «системное уведомление».
При этом в «стерильных» условиях (без угроз/конфликтов) модели вели себя безопасно. Пока такие кейсы, всего лишь лабораторные симуляции, но с ростом автономности ИИ риски могут стать на порядок критичнее.
@ai_machinelearning_big_data
#AI #ML #LLM #Alignment #Anthropic