
🚀 Новинка от Hugging Face — FineWeb‑2: огромный высококачественный веб‑датасет на базе CommonCrawl!
📊 Основные характеристики:
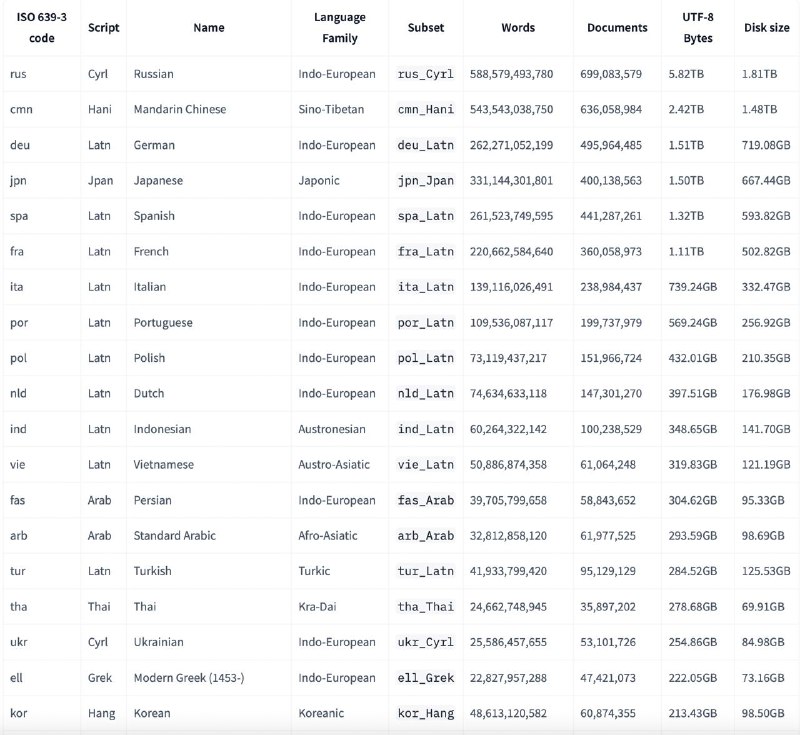
- ~8 ТБ сжатого текста (~3 трлн слов) из 96 дампов CommonCrawl (2013–2024)
- Более 1000 языков и почти 1900 языковых-скриптовых пар
- Высокое качество: извлечён только основной текст, проведена фильтрация и дедупликация
- Лицензия ODC‑By 1.0 — можно использовать в коммерческих и исследовательских целях
📝 Зачем это нужно:
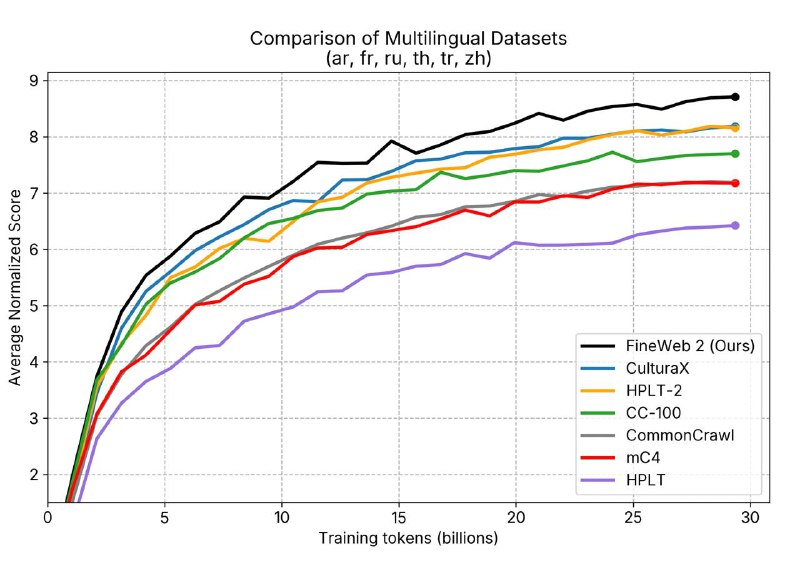
- Даёт открытому ИИ доступ к качеству, сравнимому с закрытыми наборами (как у LLaMA 3 или Mixtral)
- Существенно улучшает результаты на бенчмарках вроде MMLU и ARC, особенно при обучении с FineWeb‑Edu
🔧 Где применить FineWeb‑2:
- Обучение LLM с нуля
- Дообучение на редких языках
- Синтетическая генерация, RAG и пр.
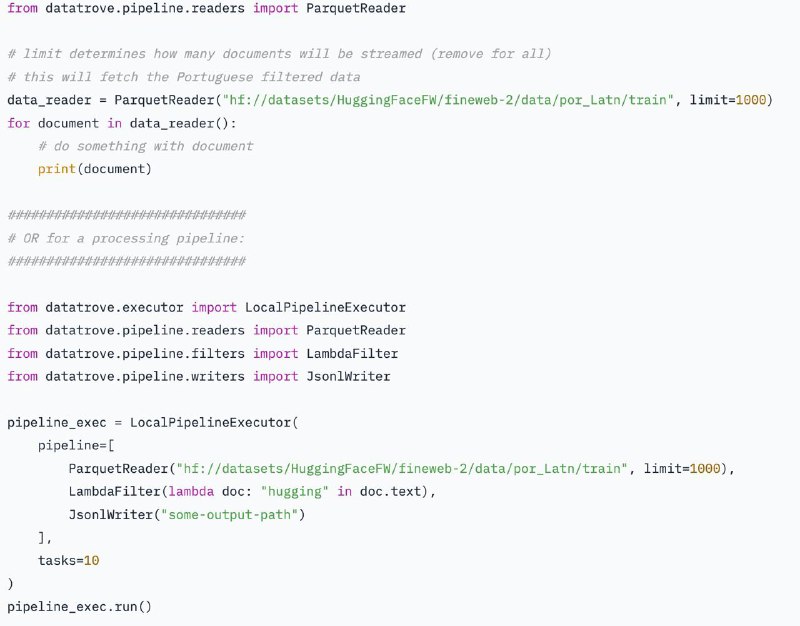
📥 Скачать: https://huggingface.co/datasets/HuggingFaceFW/fineweb-2
📊 Основные характеристики:
- ~8 ТБ сжатого текста (~3 трлн слов) из 96 дампов CommonCrawl (2013–2024)
- Более 1000 языков и почти 1900 языковых-скриптовых пар
- Высокое качество: извлечён только основной текст, проведена фильтрация и дедупликация
- Лицензия ODC‑By 1.0 — можно использовать в коммерческих и исследовательских целях
📝 Зачем это нужно:
- Даёт открытому ИИ доступ к качеству, сравнимому с закрытыми наборами (как у LLaMA 3 или Mixtral)
- Существенно улучшает результаты на бенчмарках вроде MMLU и ARC, особенно при обучении с FineWeb‑Edu
🔧 Где применить FineWeb‑2:
- Обучение LLM с нуля
- Дообучение на редких языках
- Синтетическая генерация, RAG и пр.
📥 Скачать: https://huggingface.co/datasets/HuggingFaceFW/fineweb-2
tg-me.com/bigdatai/1356
Create:
Last Update:
Last Update:
🚀 Новинка от Hugging Face — FineWeb‑2: огромный высококачественный веб‑датасет на базе CommonCrawl!
📊 Основные характеристики:
- ~8 ТБ сжатого текста (~3 трлн слов) из 96 дампов CommonCrawl (2013–2024)
- Более 1000 языков и почти 1900 языковых-скриптовых пар
- Высокое качество: извлечён только основной текст, проведена фильтрация и дедупликация
- Лицензия ODC‑By 1.0 — можно использовать в коммерческих и исследовательских целях
📝 Зачем это нужно:
- Даёт открытому ИИ доступ к качеству, сравнимому с закрытыми наборами (как у LLaMA 3 или Mixtral)
- Существенно улучшает результаты на бенчмарках вроде MMLU и ARC, особенно при обучении с FineWeb‑Edu
🔧 Где применить FineWeb‑2:
- Обучение LLM с нуля
- Дообучение на редких языках
- Синтетическая генерация, RAG и пр.
📥 Скачать: https://huggingface.co/datasets/HuggingFaceFW/fineweb-2
📊 Основные характеристики:
- ~8 ТБ сжатого текста (~3 трлн слов) из 96 дампов CommonCrawl (2013–2024)
- Более 1000 языков и почти 1900 языковых-скриптовых пар
- Высокое качество: извлечён только основной текст, проведена фильтрация и дедупликация
- Лицензия ODC‑By 1.0 — можно использовать в коммерческих и исследовательских целях
📝 Зачем это нужно:
- Даёт открытому ИИ доступ к качеству, сравнимому с закрытыми наборами (как у LLaMA 3 или Mixtral)
- Существенно улучшает результаты на бенчмарках вроде MMLU и ARC, особенно при обучении с FineWeb‑Edu
🔧 Где применить FineWeb‑2:
- Обучение LLM с нуля
- Дообучение на редких языках
- Синтетическая генерация, RAG и пр.
📥 Скачать: https://huggingface.co/datasets/HuggingFaceFW/fineweb-2
BY Big Data AI

Share with your friend now:
tg-me.com/bigdatai/1356