
tg-me.com/knowledge_accumulator/83
Last Update:
VSML [2021] - встречайте настоящие искусственные нейронные сети
Авторы во многом мотивируются мыслями, похожими на мои предыдущие посты - раз, два, три.
1) Они бросают вызов фиксированному алгоритму обучения. Backprop, апдейт весов и всё прочее задаётся человеком вручную. Если мы сможем обучать эти вещи, оптимизируя обучаемость, мы получим Meta-Learning.
2) Авторы обращают внимание, что есть 2 размерности - V_M и V_L. V_M - это размерность заданного пространства обучающих алгоритмов. А V_L - это размерность пространства "состояний" алгоритма. В случае нейросетей это количество весов. Авторы пишут - чтобы мета-алгоритм не был переобучен под семейство задач, V_L должно быть гораздо больше V_M.
И тут, в отличие от меня, авторы смогли придумать подход.
Будем обучать рекуррентную сеть с ячейками памяти, типа GRU. Но обычно у нас количество весов в ней квадратично к размеру памяти. Поэтому будем обучать много таких GRU с пошаренными весами. Сделаем из них многослойную конструкцию со связями между разными слоями в обе стороны и внутри слоя, так, чтобы у модели в теории была возможность повторить backprop. В результате у всей модели 2400 весов, а память на 257000 чисел.
Далее применяем генетический алгоритм! Как будем оценивать образцы? Будем показывать этой системе объекты (например, картинки из MNIST), считывать предсказание из последнего слоя, подавать на вход ошибку, и так много раз. В конце будем тестировать её предсказания и таким образом оценивать обучаемость.
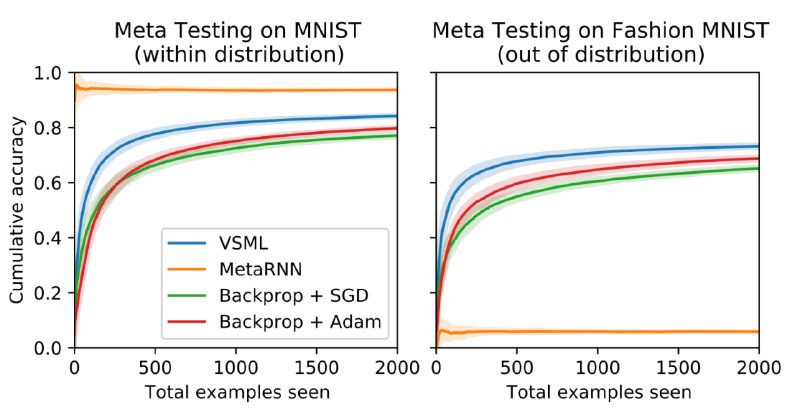
Самая потрясающая часть - это результаты сравнения с традиционным meta-rl-подходом. Когда мы сетку, обученную обучаться на MNIST, применяем на совсем другом датасете, она работает! Они обучали разные алгоритмы на 6 датасетах, тестировали на всех остальных, и везде абсолютно одинаковая картина - бейзлайн показывает ~0, а VSML работает на приличном уровне.
Я уверен, что это направление исследований и приведёт нас к настоящему интеллекту, когда идея будет отмасштабирована и применена на правильной задаче.
@knowledge_accumulator
BY Knowledge Accumulator
Share with your friend now:
tg-me.com/knowledge_accumulator/83