
tg-me.com/nlp_stuff/312
Last Update:
قطار self-supervised به ایستگاه tabular data رسید!
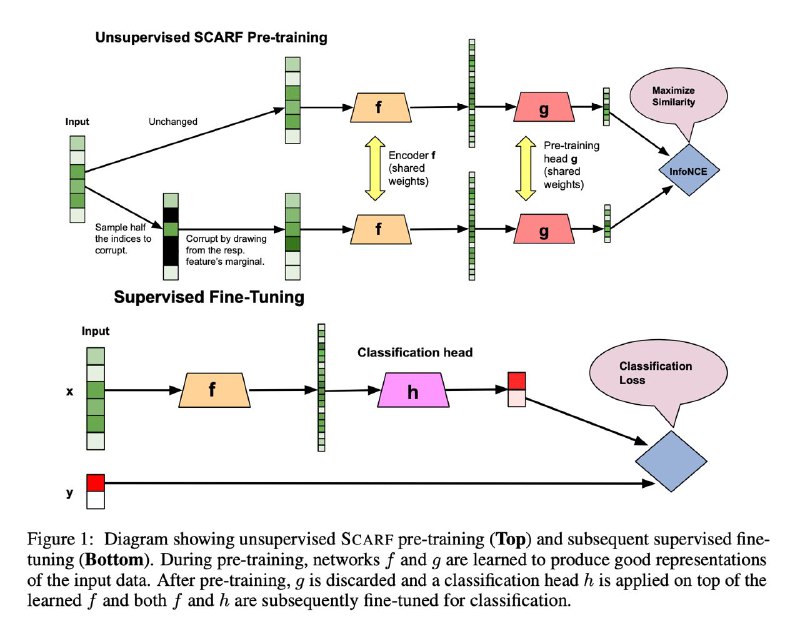
قطعا در مدح self-supervied learning زیاد شنیدید و در این پست (https://www.tg-me.com/cn/NLP stuff/com.nlp_stuff/298) هم روشهاش در NLP رو مرور کردیم. یکی از محدودیتهای اصلی self-supervised learning اینه که خیلی وابسته به دامین و مودالیتیه. مثلا روشهای حوزه تصویر به سختی برای حوزه متن قابل انجامه. حالا مردانی مرد از google research به پا خاستهاند و سعی کردند روشی عمومی برای self supervised learning ارایه کنند که حتی بر روی tabular data هم بتونه جواب بده. معماری کلی این روش رو در تصویر زیر میتونید ببینید. مانند همه روشهای SSL که در NLP بررسی کردیم، طبیعتا اینجا هم فاز pre-training و fine-tuning داریم که اساسا وجود همین پارادایم هم باعث میشه در محیطهایی که داده لیبلدار کمتری وجود داره بهتر عمل بکنه. ایده اصلی در فاز pre-training هست که از denoising auto encoderها الهام گرفته شده. در این روش به ازای یه batch از داده ترین به صورت رندم یک زیرمجموعهای از فیچرها انتخاب میشه و این فیچرها رو corrupt میکنند. روش corruption هم به این صورته که به صورت رندم با همون فیچرها از سمپلهای دیگه جایگزین میشه. حالا همونطور که در قسمت بالای تصویر میبینید دیتای سالم و دیتای corruptشده به طور همزمان (تعریف همزمان اینه که دو تا شبکه داریم که full parameter sharing انجام دادند) به یک شبکه انکودر f داده میشه که داده رو به فضای بزرگتری میبرند و سپس به یک شبکه g داده میشه که داده رو به فضای کوچکی میبره و بعد با استفاده از InfoNCE که یه loss function مشهور در عرصه SSL هست تفاوت خروجی شبکه به ازای دیتای corruptشده و دیتای سالم به دست میاد و کار ترینینگ انجام میشه (InfoNCE عملا شبیه یه categorical cross entropy عمل میکنه که به ازای نمونههای شبیه به هم مقدار کمی خروجی میده و به ازای نمونههای negative که دور از هم هستند هم مقدار زیادی رو خروجی میده).
در فاز fine tuning عملا شبکه g کنار گذاشته میشه و یک classifier head بر روی شبکه f گذاشته میشه و کل شبکه fine tune میشه.
برای تست این روش هم از دیتاست OpenML-CC18 استفاده شده که ۷۲ تسک دستهبندی داره و چون این مساله برای tabular data بوده ۳ تا از دیتاستهاش رو (CIFAR , MNIST, Fashion MNIST) کنار گذاشتند و عملا بر روی ۶۹ دیتاست تست گرفتند که روی برخی حتی با داده کمتر، بهبود هم داشته. مقاله خیلی جمع و جور و به زبان ساده و با جزییات تکنیکال نوشته شده و توصیه میکنیم حتما بخونید.
لینک مقاله:
https://arxiv.org/abs/2106.15147
لینک گیتهاب:
https://github.com/clabrugere/pytorch-scarf
#read
#paper
@nlp_stuff
BY NLP stuff
Share with your friend now:
tg-me.com/nlp_stuff/312