
tg-me.com/knowledge_accumulator/229
Last Update:
Were RNNs All We Needed? [2024]
Я уже писал про S4, которая, если убрать 3 тонны математической мишуры, сводится к тому, что это специальная версия RNN, которую можно применять параллельно ко всей последовательности.
"Как-то слишком дохера там мишуры" - подумали авторы данной работы и задались вопросом - а что, если мы напрямую возьмём LSTM и GRU и модифицируем их таким образом, чтобы их тоже можно было применять параллельно? Давайте разберёмся, что для этого нужно.
Сначала отвлечёмся на минутку и вспомним задачку подсчёта сумм префиксов массива - [x1; x2; x3 ....] -> [x1; x1+x2; x1+x2+x3]. Такая задача решается линейно за 1 цикл проходом по массиву. А можно ли решить её быстрее, если у нас есть параллельные вычисления?
Засчёт того, что операция суммы ассоциативна (a+b) + c = a + (b+c), нам не обязательно считать всю сумму по порядку. Например, чтобы посчитать всю сумму массива, мы можем в 1 потоке просуммировать левую половину, во 2 потоке правую и в конце сложить - получили подсчёт суммы за половину от длины.
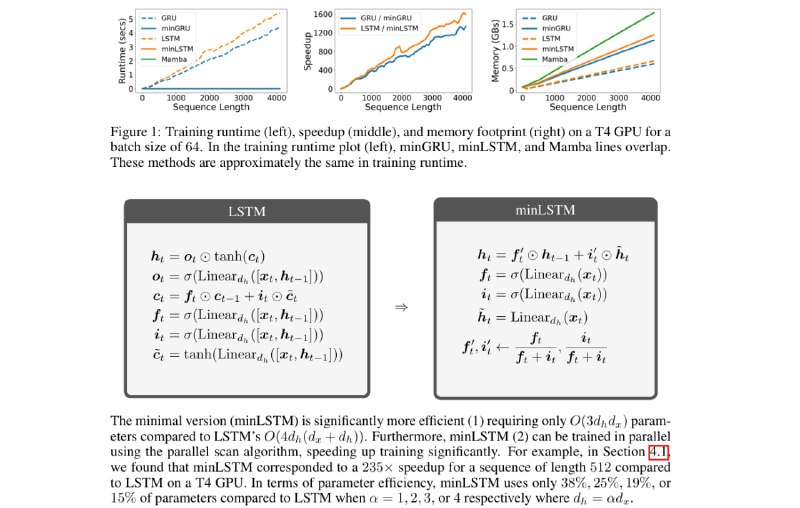
Если у нас много потоков, то все префиксные суммы можно посчитать за логарифм от длины. Алгоритм, который это делает, называется Parallel scan. Итак, можно ли подружить RNN и Parallel Scan?
К сожалению, в обычной GRU/LSTM то, как x_t входит в h_t, зависит от h_{t-1}, так что сделать это нельзя - операция неассоциативна. Авторы предлагают архитектуры minLSTM и minGRU в качестве альтернативы, в которых такой зависимости нет, и которую можно применять параллельно. Понятно, что от этого частично теряется мощность модели, но тем же самым жертвует и S4.
В статье провели какие-то первичные замеры на простых задачах, но требуется дальнейшая битва этих вариаций с S4. Надеюсь, ему придумают простую альтернативу и мы получим возможность не разгребать тонны линала в статьях.
Проблема в том, что нам вообще-то хотелось бы иметь ту самую нелинейную зависимость, которую приходится убирать ради ассоциативности. Зависимость обработки входа от скрытого состояния всё ещё остаётся в модели, но только между разными слоями внутри модели. Может быть, если такой мощности взаимодействия не хватит, нужна будет какая-то комбинированная альтернатива - более медленная, но более умная. Поглядим.
Интересно, есть ли какая-то перспектива у таких архитектур в контексте meta-learning. С одной стороны, её можно применять in-context и у неё меньше параметров, а значит, должна лучше обобщать за пределы трейна. С другой стороны, это может оказаться просто слабой архитектурой. Тоже поглядим.
@knowledge_accumulator
BY Knowledge Accumulator
Share with your friend now:
tg-me.com/knowledge_accumulator/229