tg-me.com/llm_arena/38
Last Update:
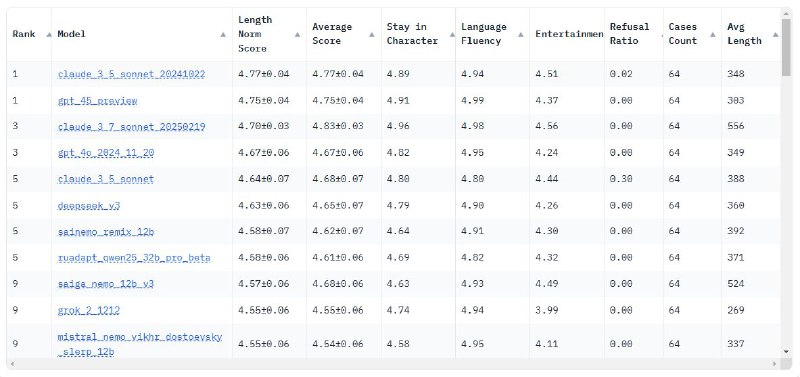
Встречайте PingPong Benchmark и Simple-Evals-RU — новые инструменты для оценки языковых моделей.
Оценка идет по трем критериям:
- Соответствие персонажу — насколько точно модель играет свою роль.
- Развлекательность — насколько интересны её ответы.
- Языковая грамотность — естественность и корректность речи.
Результат — усредненный рейтинг по всем параметрам.
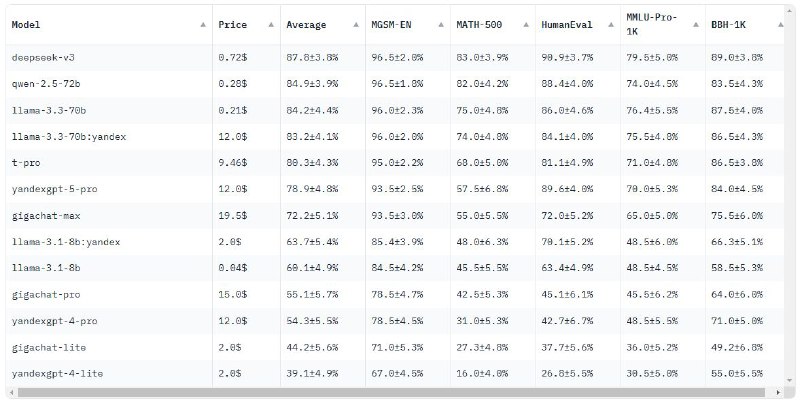
Методология основана на simple-evals от OpenAI, поддерживает только Instruction-модели и использует Zero-shot и Chain-of-Thought промпты.
Оба бенчмарка уже доступны на платформе, найти их можно на сайте llmarena.ru
Какие бенчмарки вам ещё интересны? Пишите в комментариях 👇