Люди нашли, в каких ситуациях RL отлично подходит - в решении некоторых "NP-задач" - когда вариантов решений очень много, при этом их можно осмысленно генерировать по частям. Также важно умение быстро проверять качество решения. Я уже писал про такие случаи в постах про AlphaTensor и AlphaDev.
Ради любопытства и улучшения интуиции давайте взглянем на ещё один пример, в котором это круто работает, а также подумаем о причинах успеха. Сегодняшняя "игра" - это проектирование чипов.
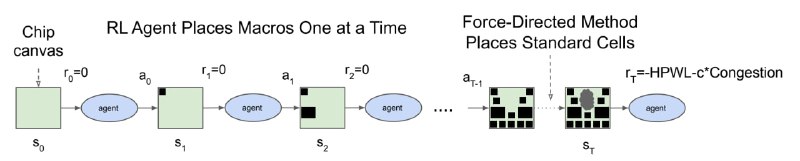
Мы начинаем с пустого "холста", и на нём один за одним располагаем элементы микросхемы, пока не расположим весь набор. После этого результат подвергается постобработке и, наконец, подсчёту награды - производится приблизительный расчёт того, насколько данная микросхема хороша, например, по суммарной длине проводов.
Пространством действий являются всевозможные позиции на холсте, на которые можно расположить текущий элемент. Состояние - это вся информация о микросхеме и уже расположенных элементах, графовая структура микросхемы, мета-фичи микросхемы и т.д. Награды нулевые на каждом шаге, кроме последнего, и там это просто мера качества результата, описанная выше.
В результате PPO, один из распространённых RL-алгоритмов, значимо обходит человека по итоговым метрикам. Почему же так получается? Заблюренные иллюстрации в статье дают на это очевидный ответ - наш интеллект не умеет решать всю задачу целиком, он вынужден разбивать её на небольшое количество кусков и затем решать каждый из них по отдельности, возможно, проделывая декомпозицию на нескольких уровнях. Итоговые микросхемы получаются у человека понятными и красивыми, тогда как алгоритм, который "на ты" с многомерными пространствами, сооружает адское месиво из тысячи компонентов, которое мы не в состоянии понять. Но оно лучше работает, а это самое главное.
Люди нашли, в каких ситуациях RL отлично подходит - в решении некоторых "NP-задач" - когда вариантов решений очень много, при этом их можно осмысленно генерировать по частям. Также важно умение быстро проверять качество решения. Я уже писал про такие случаи в постах про AlphaTensor и AlphaDev.
Ради любопытства и улучшения интуиции давайте взглянем на ещё один пример, в котором это круто работает, а также подумаем о причинах успеха. Сегодняшняя "игра" - это проектирование чипов.
Мы начинаем с пустого "холста", и на нём один за одним располагаем элементы микросхемы, пока не расположим весь набор. После этого результат подвергается постобработке и, наконец, подсчёту награды - производится приблизительный расчёт того, насколько данная микросхема хороша, например, по суммарной длине проводов.
Пространством действий являются всевозможные позиции на холсте, на которые можно расположить текущий элемент. Состояние - это вся информация о микросхеме и уже расположенных элементах, графовая структура микросхемы, мета-фичи микросхемы и т.д. Награды нулевые на каждом шаге, кроме последнего, и там это просто мера качества результата, описанная выше.
В результате PPO, один из распространённых RL-алгоритмов, значимо обходит человека по итоговым метрикам. Почему же так получается? Заблюренные иллюстрации в статье дают на это очевидный ответ - наш интеллект не умеет решать всю задачу целиком, он вынужден разбивать её на небольшое количество кусков и затем решать каждый из них по отдельности, возможно, проделывая декомпозицию на нескольких уровнях. Итоговые микросхемы получаются у человека понятными и красивыми, тогда как алгоритм, который "на ты" с многомерными пространствами, сооружает адское месиво из тысячи компонентов, которое мы не в состоянии понять. Но оно лучше работает, а это самое главное.
Some messages aren’t supposed to last forever. There are some Telegram groups and conversations where it’s best if messages are automatically deleted in a day or a week. Here’s how to auto-delete messages in any Telegram chat. You can enable the auto-delete feature on a per-chat basis. It works for both one-on-one conversations and group chats. Previously, you needed to use the Secret Chat feature to automatically delete messages after a set time. At the time of writing, you can choose to automatically delete messages after a day or a week. Telegram starts the timer once they are sent, not after they are read. This won’t affect the messages that were sent before enabling the feature.
Export WhatsApp stickers to Telegram on Android
From the Files app, scroll down to Internal storage, and tap on WhatsApp. Once you’re there, go to Media and then WhatsApp Stickers. Don’t be surprised if you find a large number of files in that folder—it holds your personal collection of stickers and every one you’ve ever received. Even the bad ones.Tap the three dots in the top right corner of your screen to Select all. If you want to trim the fat and grab only the best of the best, this is the perfect time to do so: choose the ones you want to export by long-pressing one file to activate selection mode, and then tapping on the rest. Once you’re done, hit the Share button (that “less than”-like symbol at the top of your screen). If you have a big collection—more than 500 stickers, for example—it’s possible that nothing will happen when you tap the Share button. Be patient—your phone’s just struggling with a heavy load.On the menu that pops from the bottom of the screen, choose Telegram, and then select the chat named Saved messages. This is a chat only you can see, and it will serve as your sticker bank. Unlike WhatsApp, Telegram doesn’t store your favorite stickers in a quick-access reservoir right beside the typing field, but you’ll be able to snatch them out of your Saved messages chat and forward them to any of your Telegram contacts. This also means you won’t have a quick way to save incoming stickers like you did on WhatsApp, so you’ll have to forward them from one chat to the other.