
tg-me.com/knowledge_accumulator/237
Last Update:
The Surprising Effectiveness of Test-Time Training for Abstract Reasoning [2024] - так что, трансформеры работают на ARC?
Вы могли читать в соседних каналах о том, что LLM смогли приспособить для решения ARC - теста на способность распознавать и применять паттерны по нескольким обучающим примерам. Многие топовые решения основываются на поиске программ, тогда как применение GPT-4 / o1 даёт весьма скромный результат.
В данной работе авторы добавили в LLM-пайплайн несколько улучшений, позволивших получить результат в 62% - число, немного превышающее Avg. Human. Давайте разберёмся, как к этому пришли.
Изначальную LLama файнтюнят с помощью так называемого ReARC - датасету из искусственно сгенерированных задач. Чтобы их получить, был выписан набор элементарных трансформаций над плоскостями, из которых составлялись задачи и образцы. Из этого добра составлялись сэмплы для few-shot in-context обучения. Она решает 5 задач из 80.
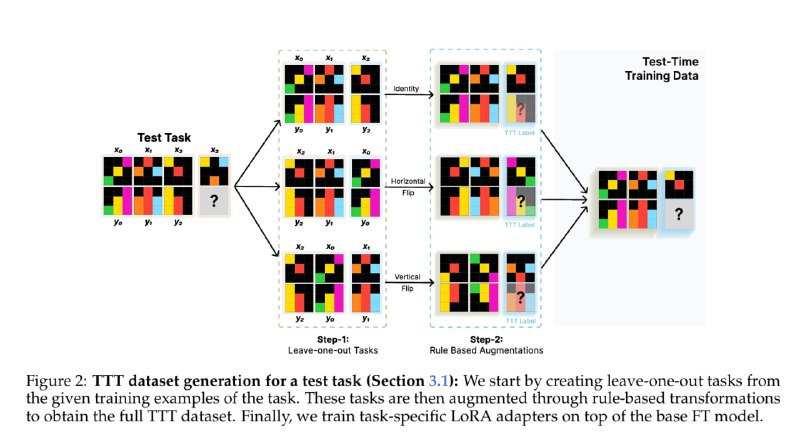
Далее наступает Test-Time Training. Получив датасет из N тренировочных пар вход-выход, мы строим следующий датасет для In-Context Learning:
1) Берём каждый из N сэмплов и превращаем в таргет для in-context обучения, т.е. подаём на вход N-1 сэмплов с таргетами и предсказываем N-ный выход.
2) Обкладываем всё дата-аугментациями - симметрии, повороты, перемешивание тренировочных пар, скейлинг. Молимся, чтобы это не повлияло на задачу.
3) Дополнительно, обучаемся предсказывать таргеты со 2-го по N-1-й, это в статье называют Demonstration loss.
Обучаем LoRA (малопараметрический файнтюн) на каждую отдельную задачку в ARC на описанном выше датасете. Во время тестирования, применяем аугментации к задаче и потом ревёрсим обратно предсказанный ответ. Для выбора 2 финальных ответов проводятся выборы. Всё это в сумме даёт 29 задач из 80. Давайте глянем на Ablation:
1) Если обучать одну LoRA на все задачи - 22 / 80
2) Если не применять дата-аугментации - 13 / 80
3) Если вместо хитрого in-context test-time training просто файнтюнить на N сэмплах - 18 / 80
4) Если не файнтюнить модель на ReARC - 9 / 80
5) Если попросить GPT-4o сгенерировать ARC задачи для файнтюна и добавить к ReARC - 24 / 80 😁
Все эти замеры проводились на основе LLama-1B, Llama-8B даёт уже 36 из 80 - результат в 45%. А откуда же взялся результат в 62%? Для этого авторы совместили свою статью с другим подходом - статьёй BARC, про которую я расскажу в следующий раз. Применяя test-time training к нейросети из BARC, получается 53%. Чтобы получить 62%, нужно ансамблировать решение с синтезатором программ.
Интересно, какой был бы результат у всего этого на реальном тестовом ARC-датасете. Могу поверить, что какой-то близкий к этому числу, но теоретически возможны и лики. Всё-таки, авторы тюнили все детали своего подхода на наборе из 80 задач, кроме того, датасет для файтнюна (без которого это почти не работает) теоретически мог содержать операции, слишком близкие к public validation. Именно эти опасности и устраняются наличием полностью секретного тестового датасета.
О том, что нам этот результат даёт в более широком контексте. мы поговорим потом, а пока что просто порадуемся за команду.
@knowledge_accumulator
BY Knowledge Accumulator
Share with your friend now:
tg-me.com/knowledge_accumulator/237