🤖 Почему модели лучше отвечают на вопросы по тексту, чем по изображениям — и как это исправить?
Vision-Language модели (VLMs) сильно хуже справляются с вопросами про картинки (*«Сколько книг на изображении?»*), чем с теми же вопросами по тексту (*«Сколько книг в описании?»*). И нашли способ улучшить результат на +4.6%, закрыв треть разрыва между модальностями! Вот что они сделали 👇
🔬 Они разделили вход на три части: • Данные (изображение или текст), • Вопрос (*how many…*), • Ответ (предсказание последнего слова).
🧠 Что нашли:
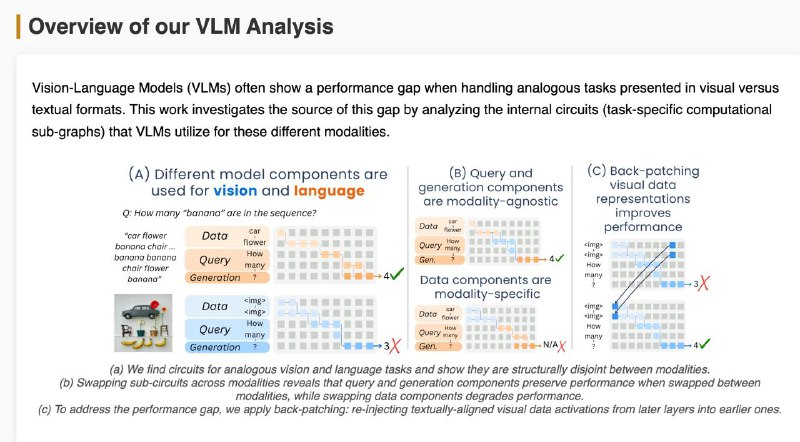
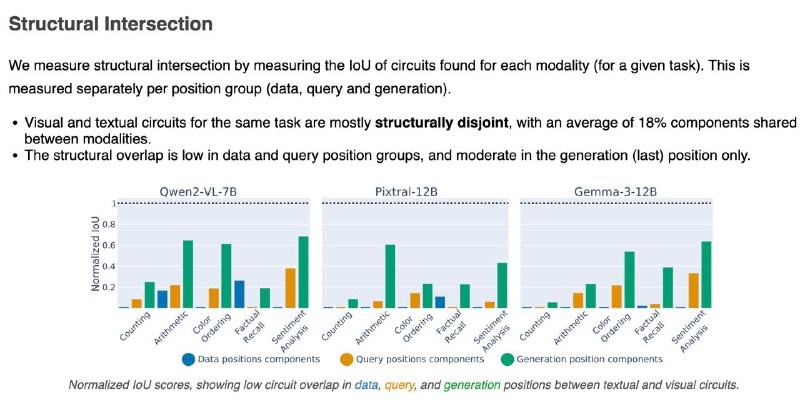
1️⃣Мозги у модели разные для текста и картинок — цепочки внимания и нейроны почти не совпадают (всего ~18%). Особенно в частях, где обрабатываются данные и вопрос.
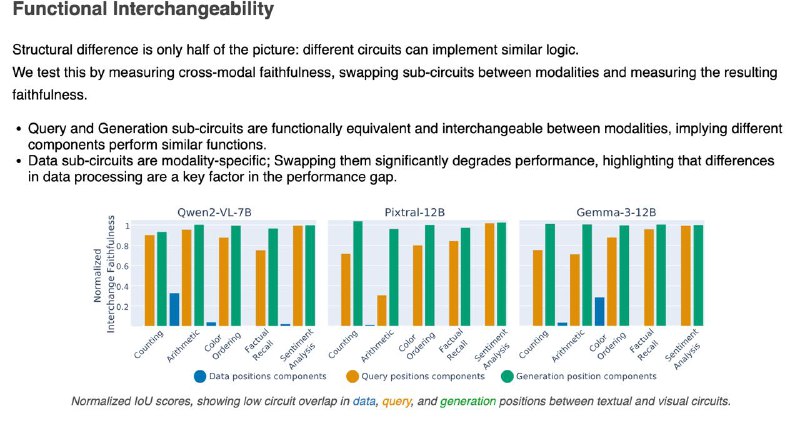
2️⃣Часть, отвечающая за генерацию ответа, похожа — можно даже подменить её между модальностями, и модель почти не теряет в точности.
3️⃣Часть, которая "смотрит" на данные — строго модальная. Визуальный поток информации идёт по другому пути, и замена разрушает результат.
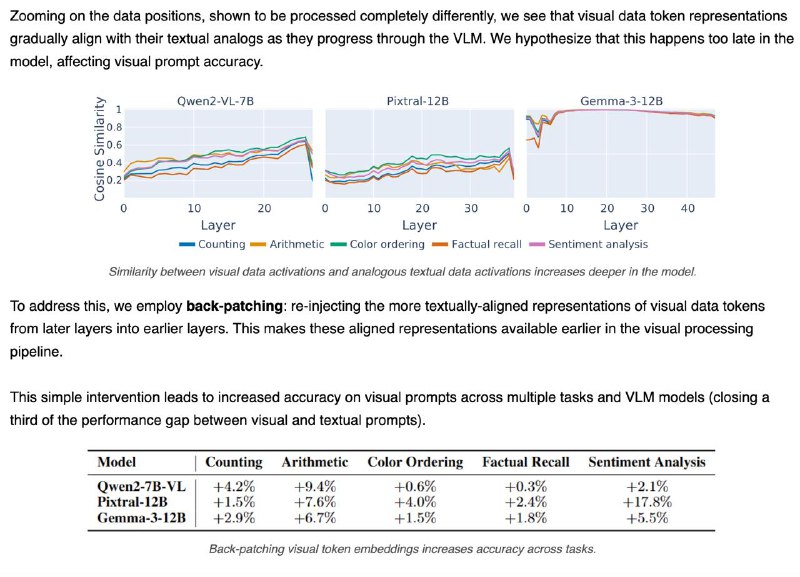
4️⃣Проблема в том, что изображение “становится понятным” слишком поздно. В поздних слоях визуальные данные уже похожи на текстовые — но модель не успевает этим воспользоваться.
💡 Решение: "перемотать" визуальные данные из поздних слоёв обратно в ранние (back-patching) — это помогает модели раньше "понять" картинку.
📈 Результат: +4.6% точности при ответах на вопросы по изображению — и треть разрыва с текстом закрыта!
🧩 Вывод: архитектура не виновата. Просто визуальные данные нужно правильно "подать" — и VLM начинает думать почти как человек.
🤖 Почему модели лучше отвечают на вопросы по тексту, чем по изображениям — и как это исправить?
Vision-Language модели (VLMs) сильно хуже справляются с вопросами про картинки (*«Сколько книг на изображении?»*), чем с теми же вопросами по тексту (*«Сколько книг в описании?»*). И нашли способ улучшить результат на +4.6%, закрыв треть разрыва между модальностями! Вот что они сделали 👇
🔬 Они разделили вход на три части: • Данные (изображение или текст), • Вопрос (*how many…*), • Ответ (предсказание последнего слова).
🧠 Что нашли:
1️⃣Мозги у модели разные для текста и картинок — цепочки внимания и нейроны почти не совпадают (всего ~18%). Особенно в частях, где обрабатываются данные и вопрос.
2️⃣Часть, отвечающая за генерацию ответа, похожа — можно даже подменить её между модальностями, и модель почти не теряет в точности.
3️⃣Часть, которая "смотрит" на данные — строго модальная. Визуальный поток информации идёт по другому пути, и замена разрушает результат.
4️⃣Проблема в том, что изображение “становится понятным” слишком поздно. В поздних слоях визуальные данные уже похожи на текстовые — но модель не успевает этим воспользоваться.
💡 Решение: "перемотать" визуальные данные из поздних слоёв обратно в ранние (back-patching) — это помогает модели раньше "понять" картинку.
📈 Результат: +4.6% точности при ответах на вопросы по изображению — и треть разрыва с текстом закрыта!
🧩 Вывод: архитектура не виновата. Просто визуальные данные нужно правильно "подать" — и VLM начинает думать почти как человек.
The cloud-based messaging platform is also adding Anonymous Group Admins feature. As per Telegram, this feature is being introduced for safer protests. As per the Telegram blog post, users can “Toggle Remain Anonymous in Admin rights to enable Batman mode. The anonymized admin will be hidden in the list of group members, and their messages in the chat will be signed with the group name, similar to channel posts.”
Export WhatsApp stickers to Telegram on iPhone
You can’t. What you can do, though, is use WhatsApp’s and Telegram’s web platforms to transfer stickers. It’s easy, but might take a while.Open WhatsApp in your browser, find a sticker you like in a chat, and right-click on it to save it as an image. The file won’t be a picture, though—it’s a webpage and will have a .webp extension. Don’t be scared, this is the way. Repeat this step to save as many stickers as you want.Then, open Telegram in your browser and go into your Saved messages chat. Just as you’d share a file with a friend, click the Share file button on the bottom left of the chat window (it looks like a dog-eared paper), and select the .webp files you downloaded. Click Open and you’ll see your stickers in your Saved messages chat. This is now your sticker depository. To use them, forward them as you would a message from one chat to the other: by clicking or long-pressing on the sticker, and then choosing Forward.