
tg-me.com/python_academy/744
Last Update:
Работаем с данными
pandas - это мощный инструмент для анализа данных в Python. С помощью данного фреймворка, работа с «реляционными» или «помеченными» данными простой и интуитивно понятной. Сегодня мы применим его для модификации csv файла.
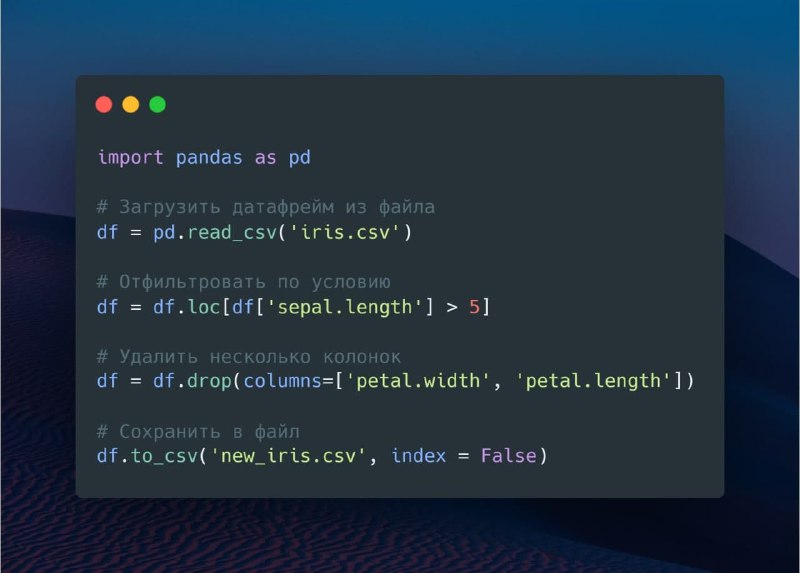
Чтобы загрузить датафрейм из файла (пример), используем метод pd.read_csv().
Применим фильтр по полю sepal.length > 5. В SQL данная операция выглядела бы таким образом:SELECT * FROM df WHERE sepal.length > 5.
В pandas же для получения необходимых строк фрейма можем использовать метод loc, передав в нее необходимый фильтр: df = df.loc[df['sepal.length'] > 5]
Для удаления одной или нескольких колонок можно использовать метод df.drop():df = df.drop(columns=['petal.width', 'petal.length'])
При сохранении в файл мы можем дополнительно указать pandas не добавлять генерирующийся индекс строкам, если он нам не нужен:df.to_csv('new_iris.csv', index = False)
#pandas
BY Python Academy
Share with your friend now:
tg-me.com/python_academy/744