tg-me.com/github_code/337
Last Update:
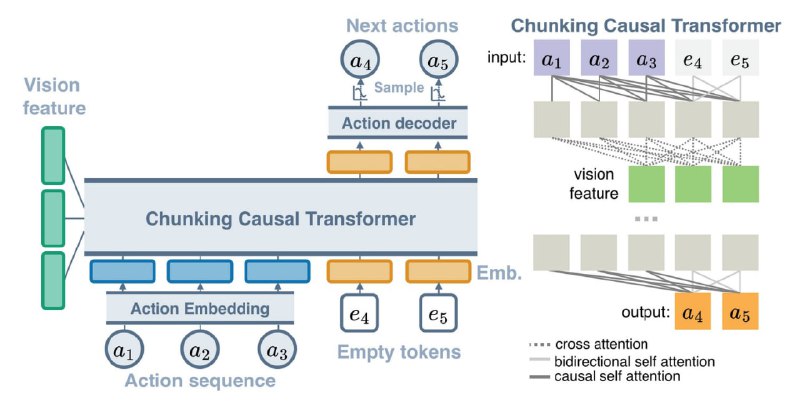
ARP - архитектура авторегрессионной политики, разработанная в Рутгерском университете, которая учится генерировать последовательности действий, используя Chunking Causal Transformer (CCT), предлагая универсальный подход, превосходящий специализированные решения для задач манипулирования.
Политика предсказывает только будущую последовательность действий на основе текущего состояния (или наблюдения), не пытаясь предсказать всю траекторию. Этот метод обучения последовательности действий более достижим в приложениях робототехники и позволяет лучше использовать причинно-следственные связи.
ARP состоит из трех основных компонентов:
ARP оценивался в 3 средах (Push-T, ALOHA, RLBench) и сравнивался с современными методами для каждой среды. Во всех случаях ARP продемонстрировал высокую производительность, достигая SOTA-показателей при меньших вычислительных затратах.
ARP был протестирован в реальном эксперименте с роботом, где он успешно выполнил сложную задачу по затягиванию гаек.
В репозитории проекта доступен код для обучения, тестирования в средах Push-T, ALOHA, RLBench и подробные инструкции по настройке окружения под каждую из этих задач.
⚠️ В зависимости от задачи (Push-T, ALOHA или RLBench) необходимо выбрать соответствующий файл конфигурации. Примеры конфигурационных файлов приведены в файле Experiments.md
⚠️ Форматы данных для каждой задачи разные:
@ai_machinelearning_big_data
#AI #ML #Robotics #ARP