tg-me.com/machinelearning_interview/1595
Last Update:
Проект написан на CUDA и рассчитан исключительно на использование тензорных ядер архитектуры NVIDIA Hopper, что уже само по себе делает его очень современным
В основе DeepGEMM лежит идея максимально эффективного выполнения операций умножения матриц с использованием 8-битной точности.
Для решения проблемы накопления в FP8 (которое может давать неточные результаты) разработчики внедрили двухуровневое накопление, которое использует возможности CUDA-ядра для повышения точности без потери производительности.
Что действительно радует – это минимализм кода.
✔ Ядро библиотеки представлено всего в одном ключевом модуле, состоящем примерно из 300 строк, что позволяет легко разобраться в его работе и даже внести собственные улучшения.
При этом все ядра компилируются «на лету» с помощью легковесного JIT-компилятора, так что нет долгого этапа сборки при установке.
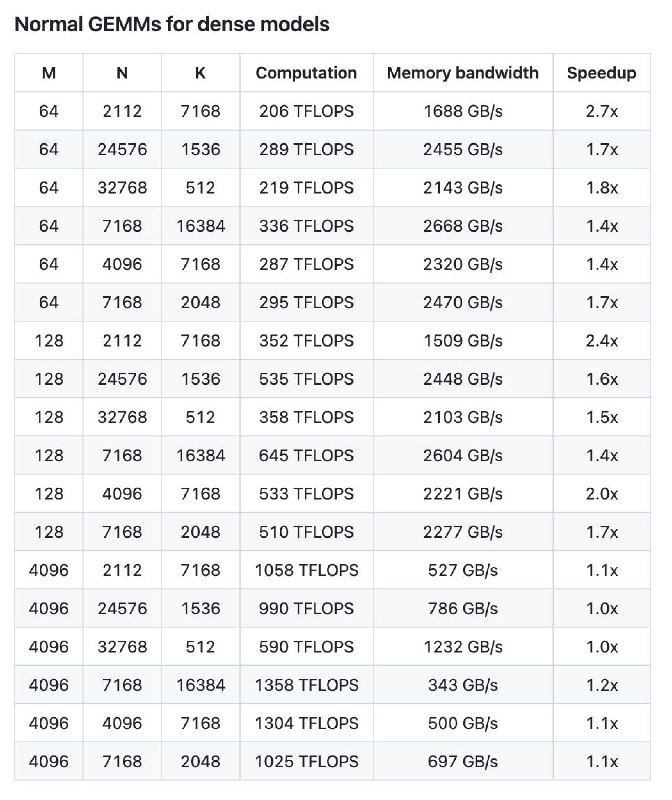
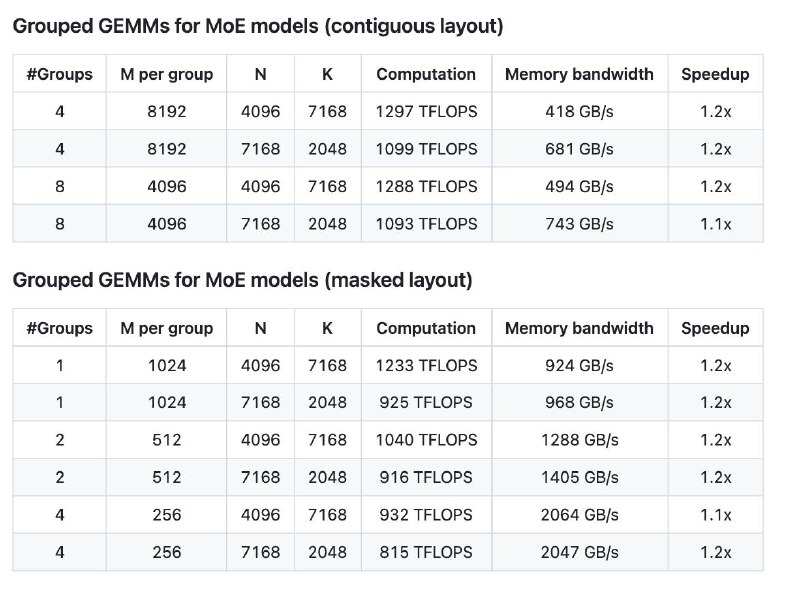
DeepGEMM поддерживает разные режимы работы: обычные GEMM для плотных моделей, а также группированные операции для моделей типа Mix-of-Experts, где требуется обрабатывать данные в нескольких форматах – как в «континуальном», так и в «masked» виде. Это особенно актуально для современных решений в области глубокого обучения.
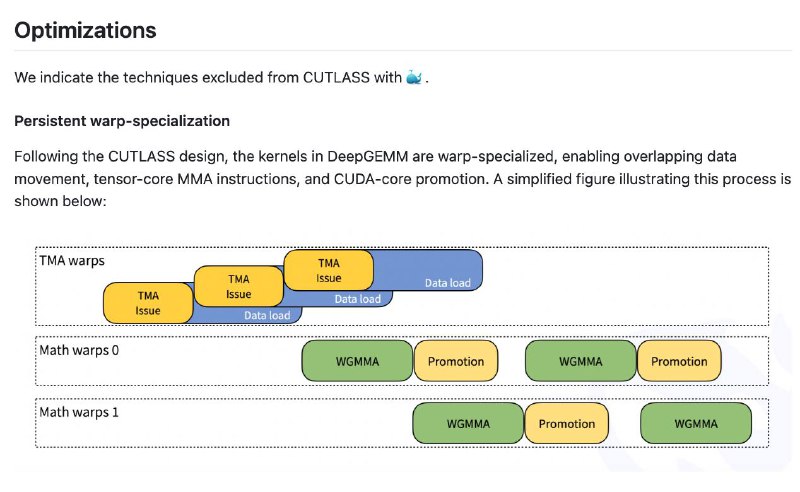
Оптимизации, заложенные в DeepGEMM, включают использование новых функций Hopper, таких как Tensor Memory Accelerator (TMA) для асинхронной передачи данных, а также тонкую настройку блоковых размеров и оптимизацию инструкций FFMA для лучшего перекрытия вычислений и загрузки данных. Результаты говорят сами за себя: производительность этой библиотеки на ряде тестовых примеров сравнима или даже превосходит решения, построенные на базе CUTLASS.
DeepGEMM – это лаконичный и эффективный инструмент, который может послужить отличной базой для исследований и практических разработок в области ускорения вычислений для глубокого обучения.
▪ Github
#ai #deepseek #opensource #DeepEP #OpenSourceWeek: