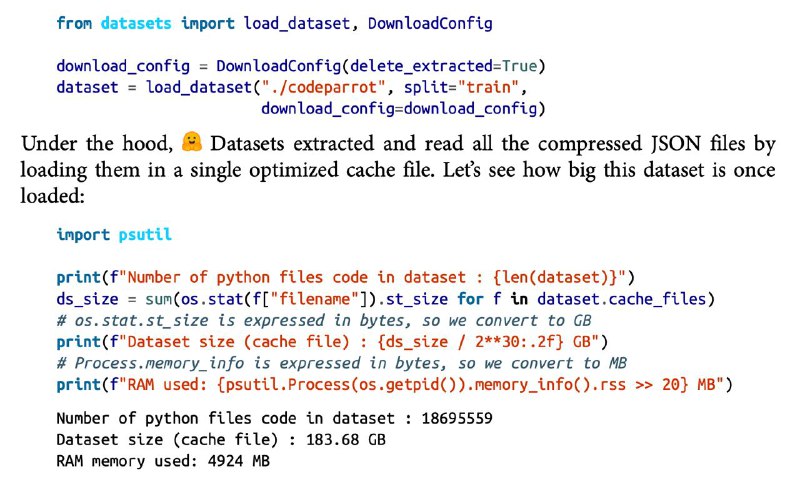
احتمالا تا حالا شده که در مسیر تسکهای NLP به دیوار سخت و خشن یک دیتاست بزرگ برخورده باشید (مثلا یک دیتاست در اندازه چند ده گیگابایت که شاید حتی جایی برای ذخیرهسازیش در دیسک نداشته باشید چه برسه به رم). در این حالته که دستها رو به نشانه تسلیم بالا میبرید. اما هاگینگفیس در کتابخانه Datasets🤗 این مشکل رو حل کرده. در واقع با دو قابلیت memory mapping و streaming که این کتابخانه فراهم کرده بر محدودیت رم و دیسک غلبه میکنید. قابلیت memory mapping (که به صورت پیشفرض فعاله) به این اشاره داره که با لودکردن هر دیتاستی توسط Datasets🤗 این کتابخانه یه سری cache file از دیتاست میسازه که بر روی دیسک ذخیره شدند و عینا همون محتویات دیتاست لودشده در RAM هستند. پس یه جور آیینه تمامنمای RAM محسوب میشه و از این جا به بعد دیگه این کتابخانه یه اشارهگر به اول این فایل باز میکنه و دیتا به صورت batch داخل رم لود میشه. طبیعتا آموزش مدل از اینجا به بعد I/O bounded خواهد بود اما نگران اون قسمتش هم نباشید چون فرمتی که برای کار با این فایلها استفاده میکنه Apache Arrow هست که یه فرمت بهینهشده است. از طرفی برای اینکه نعمت رو بر ما تکمیل کرده باشه و حتی نگران کمبود دیسک هم نباشیم قابلیت streaming رو تعریف کرده که ینی میتونید از هاب دیتاست هاگینگفیس، دیتاست رو به صورت batch و on the fly دانلود کنید و پردازش انجام بدید (که به صورت پیشفرض فعال نیست و باید streaming=True باشه). البته با استفاده از این قابلیت امکان random access به دیتاها رو از دست میدید (مثلا نمیتونید دستور dataset[2335] رو ران کنید چون آبجکتی که میسازه حالت iterable داره و شبیه generatorهای پایتونیه) ولی با دستور next و iterate کردن بر روی دیتاست، دقیقا سمپلهای یک دیتاست استریمنشده رو میگیرید. پس دیگه بهونه بسه و پاشید کار با دیتاستهای بزرگ رو شروع کنید.
پ.ن: در تصاویر یه سری نمونه کدهایی آوردیم که از فصل ۱۰ کتاب گرانسنگ NLP with Transformers گرفته شده که اثری جاوید از هاگینگفیسه.
احتمالا تا حالا شده که در مسیر تسکهای NLP به دیوار سخت و خشن یک دیتاست بزرگ برخورده باشید (مثلا یک دیتاست در اندازه چند ده گیگابایت که شاید حتی جایی برای ذخیرهسازیش در دیسک نداشته باشید چه برسه به رم). در این حالته که دستها رو به نشانه تسلیم بالا میبرید. اما هاگینگفیس در کتابخانه Datasets🤗 این مشکل رو حل کرده. در واقع با دو قابلیت memory mapping و streaming که این کتابخانه فراهم کرده بر محدودیت رم و دیسک غلبه میکنید. قابلیت memory mapping (که به صورت پیشفرض فعاله) به این اشاره داره که با لودکردن هر دیتاستی توسط Datasets🤗 این کتابخانه یه سری cache file از دیتاست میسازه که بر روی دیسک ذخیره شدند و عینا همون محتویات دیتاست لودشده در RAM هستند. پس یه جور آیینه تمامنمای RAM محسوب میشه و از این جا به بعد دیگه این کتابخانه یه اشارهگر به اول این فایل باز میکنه و دیتا به صورت batch داخل رم لود میشه. طبیعتا آموزش مدل از اینجا به بعد I/O bounded خواهد بود اما نگران اون قسمتش هم نباشید چون فرمتی که برای کار با این فایلها استفاده میکنه Apache Arrow هست که یه فرمت بهینهشده است. از طرفی برای اینکه نعمت رو بر ما تکمیل کرده باشه و حتی نگران کمبود دیسک هم نباشیم قابلیت streaming رو تعریف کرده که ینی میتونید از هاب دیتاست هاگینگفیس، دیتاست رو به صورت batch و on the fly دانلود کنید و پردازش انجام بدید (که به صورت پیشفرض فعال نیست و باید streaming=True باشه). البته با استفاده از این قابلیت امکان random access به دیتاها رو از دست میدید (مثلا نمیتونید دستور dataset[2335] رو ران کنید چون آبجکتی که میسازه حالت iterable داره و شبیه generatorهای پایتونیه) ولی با دستور next و iterate کردن بر روی دیتاست، دقیقا سمپلهای یک دیتاست استریمنشده رو میگیرید. پس دیگه بهونه بسه و پاشید کار با دیتاستهای بزرگ رو شروع کنید.
پ.ن: در تصاویر یه سری نمونه کدهایی آوردیم که از فصل ۱۰ کتاب گرانسنگ NLP with Transformers گرفته شده که اثری جاوید از هاگینگفیسه.
Spiking bond yields driving sharp losses in tech stocks
A spike in interest rates since the start of the year has accelerated a rotation out of high-growth technology stocks and into value stocks poised to benefit from a reopening of the economy. The Nasdaq has fallen more than 10% over the past month as the Dow has soared to record highs, with a spike in the 10-year US Treasury yield acting as the main catalyst. It recently surged to a cycle high of more than 1.60% after starting the year below 1%. But according to Jim Paulsen, the Leuthold Group's chief investment strategist, rising interest rates do not represent a long-term threat to the stock market. Paulsen expects the 10-year yield to cross 2% by the end of the year.
A spike in interest rates and its impact on the stock market depends on the economic backdrop, according to Paulsen. Rising interest rates amid a strengthening economy "may prove no challenge at all for stocks," Paulsen said.
Export WhatsApp stickers to Telegram on Android
From the Files app, scroll down to Internal storage, and tap on WhatsApp. Once you’re there, go to Media and then WhatsApp Stickers. Don’t be surprised if you find a large number of files in that folder—it holds your personal collection of stickers and every one you’ve ever received. Even the bad ones.Tap the three dots in the top right corner of your screen to Select all. If you want to trim the fat and grab only the best of the best, this is the perfect time to do so: choose the ones you want to export by long-pressing one file to activate selection mode, and then tapping on the rest. Once you’re done, hit the Share button (that “less than”-like symbol at the top of your screen). If you have a big collection—more than 500 stickers, for example—it’s possible that nothing will happen when you tap the Share button. Be patient—your phone’s just struggling with a heavy load.On the menu that pops from the bottom of the screen, choose Telegram, and then select the chat named Saved messages. This is a chat only you can see, and it will serve as your sticker bank. Unlike WhatsApp, Telegram doesn’t store your favorite stickers in a quick-access reservoir right beside the typing field, but you’ll be able to snatch them out of your Saved messages chat and forward them to any of your Telegram contacts. This also means you won’t have a quick way to save incoming stickers like you did on WhatsApp, so you’ll have to forward them from one chat to the other.