tg-me.com/opendatascience/2337
Last Update:
Improving the Diffusability of Autoencoders
Сегодня разбираем статью, в которой обсуждается то, что авторы называют diffusability латентного пространства: насколько легко диффузионной модели учиться на латентах автоэнкодера.
В латентных диффузионных моделях (например, Stable Diffusion) генерация происходит не в пикселях, а в сжатом представлении. Это ускоряет обучение, но вводит зависимость от свойств автоэнкодера. Обычно смотрят только на качество реконструкции: насколько хорошо декодер восстанавливает изображение. Но есть вторая характеристика — diffusability, и именно её авторы рассматривают в этой работе.
Что такое diffusability и почему это важно
Если латенты имеют сложное распределение или содержат неинформативные шумовые компоненты, диффузии приходится подстраиваться под это распределение — обучаться дольше и потенциально упираться в потолок качества. Поэтому автоэнкодер задаёт не только качество реконструкции, но и удобство обучения вместе с последующей генерацией.
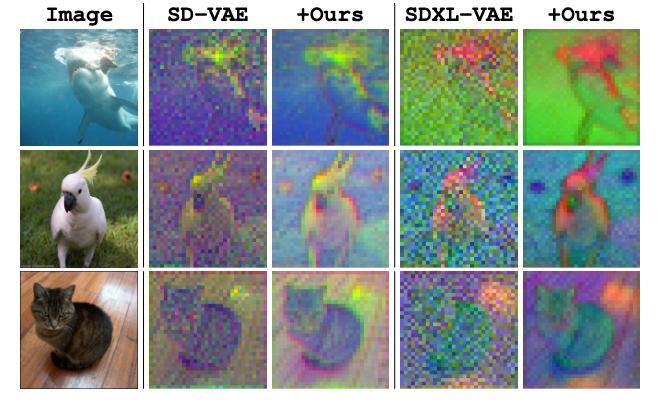
Авторы смотрят на латенты от обычных автоэнкодеров и замечают, что они визуально шумные: в них много высокочастотных деталей, особенно в фоне. Чтобы разобраться, применяют дискретное косинусное преобразование (DCT), как в JPEG. Разбивают картинку или латент на блоки 8×8, считают DCT по каждому из них, усредняют спектры и строят частотный профиль.
Выясняется, что латенты содержат больше высокочастотных компонентов, чем изображения, и это особенно заметно при увеличении числа каналов. Даже если латент визуально похож на картинку, его частотный профиль сильно отличается. А если обнулить высокие частоты и попробовать восстановить изображение, латент теряет качество гораздо сильнее, чем обычное изображение — там такие потери почти незаметны. Это говорит о том, что латенты слишком зависят от высокочастотной части и не обладают масштабной эквивариантностью.
Тогда авторы добавляют к лоссу автоэнкодера простую компоненту: берут исходное изображение и соответствующий латент, уменьшают их разрешение (в 2 или 4 раза), затем реконструируют картинку из сжатого латента и считают дополнительный лосс между даунскейленным изображением и полученной реконструкцией.
Таким образом они обеспечивают соблюдения свойства масштабной инвариантности (потому что лосс буквально это и делает), что, в свою очередь, регуляризует латенты, убирая из них лишние высокие частоты.
Результат — латенты становятся менее шумными, частотные профили ближе к тем, что у изображений. И, что важно, визуально структура латента сохраняется. Согласно метрикам, качество реконструкции почти не падает.
Эксперименты
Метод протестировали на ImageNet-1K (изображения) и Kinetics-700 (видео). Сравнивали обучение диффузионной модели на обычных и исправленных латентах.
В статье diffusability измеряют через скорость обучения: берут автоэнкодер, обучают на нём диффузионную модель и смотрят, насколько быстро растёт метрика качества (например, FID для изображений и FVD для видео). Сравнивались базовые модели и те же архитектуры, но обученные на автоэнкодерах с исходным и улучшенным diffusability. Оказалось, что последние учатся быстрее и дают лучшее финальное качество.
Результаты:
— генерация изображений: FID улучшился на 19%;
— генерация видео: FVD улучшился на 44%;
— модели обучаются быстрее;
— PSNR немного растёт (за счёт блюра), но визуально картинки выглядят нормально.
Визуализация того, как выглядят латенты до и после (см. картинку), взята из другой работы, посвященной этой же теме: шум действительно уходит, но структура остаётся. Частотные кривые тоже приближаются к тем, что у изображений.
В целом статья посвящена довольно локальной проблеме, но в ней есть понятная идея и измеримый эффект.
Разбор подготовил
CV Time