
Forwarded from Machinelearning
🚀 Парадигма меняется: Polaris выводит локальные модели на новый уровень
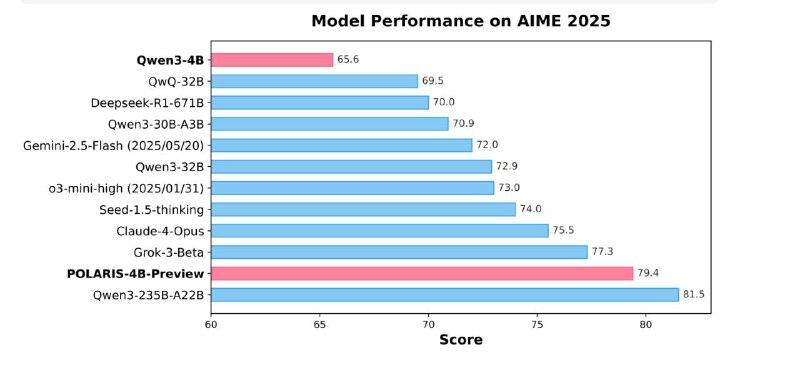
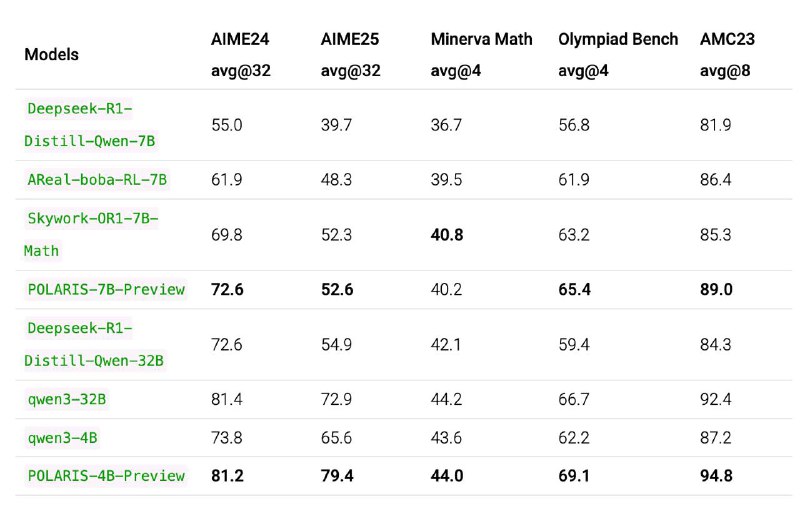
Polaris — это набор простых, но мощных приёмов, который позволяет даже компактным LLM (4 B, 7 B) догнать и превзойти «тяжеловесов» на задачах рассуждения (открытая 4B модель превосходи Claude-4-Opus).
Вот как это работает и почему важно:
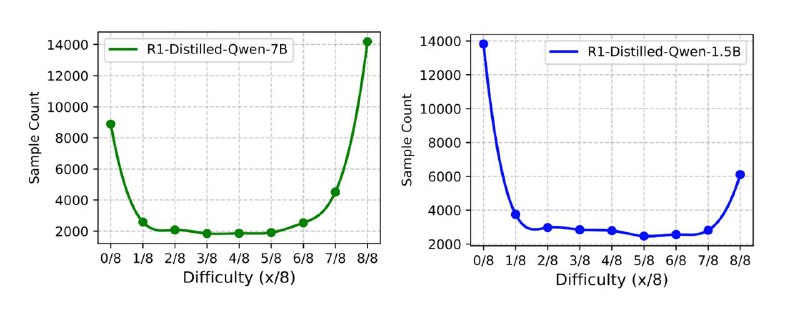
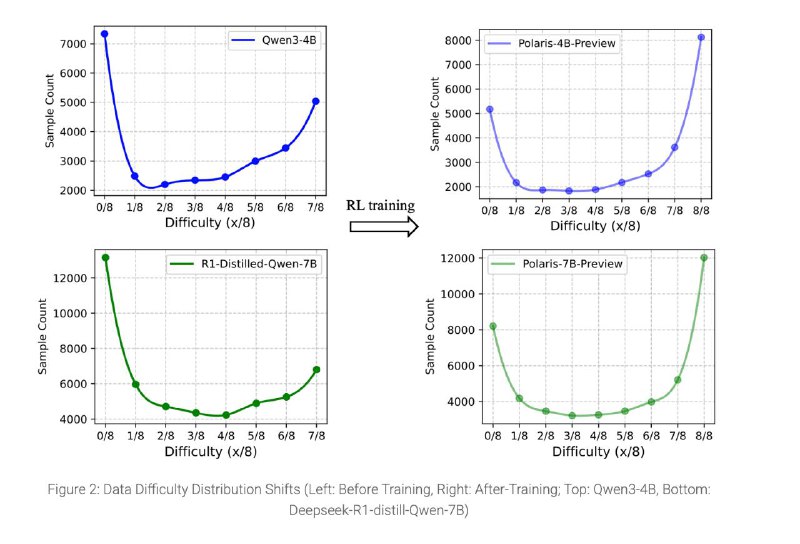
• Управление сложностью данных
– Генерируем несколько (например, 8) вариантов решения от базовой модели
– Оцениваем, какие примеры слишком простые (8/8) или слишком сложные (0/8), и убираем их
– Оставляем «умеренные» задачи с правильными решениями в 20–80 % случаев, чтобы быть ни слишком лёгкими, ни слишком сложными
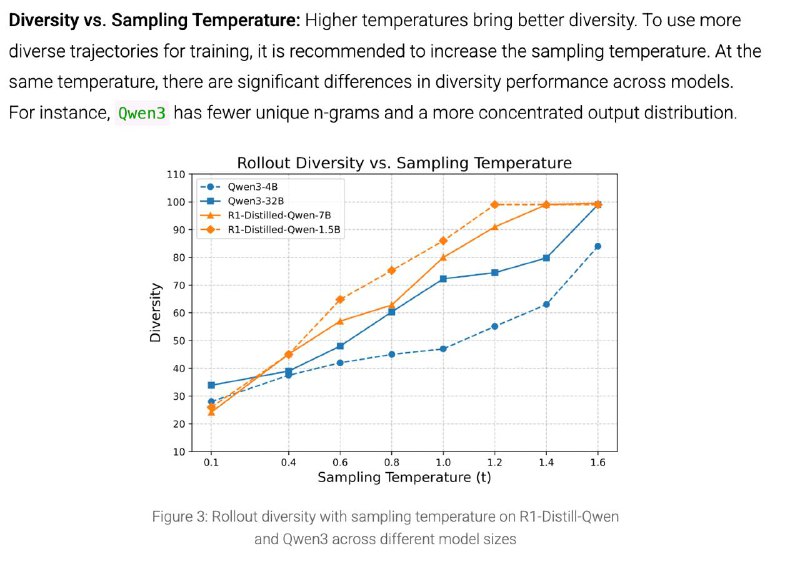
• Разнообразие «прогонов» (rollout-ов)
– Мы запускаем модель несколько раз на одной и той же задаче и смотрим, как меняются её рассуждения: одни и те же входные данные, но разные «пути» к решению.
– Считаем, насколько разнообразны эти пути (т. е. их «энтропия»): если модели всё время идут по одной линии, новых идей не появляется; если слишком хаотично — рассуждения неустойчивы.
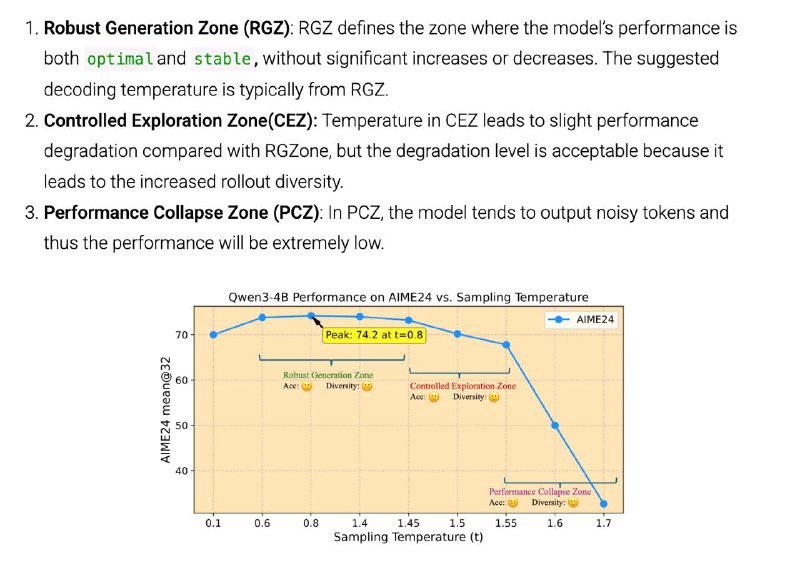
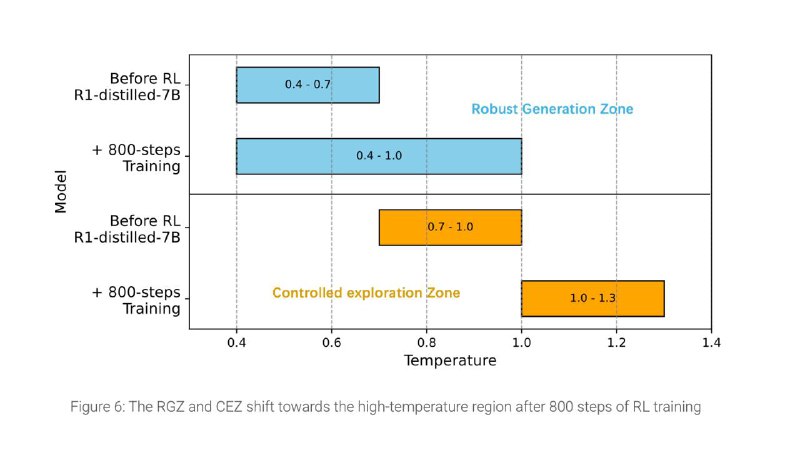
– Задаём начальную “температуру” генерации там, где баланс между стабильностью и разнообразием оптимален, а затем постепенно её повышаем, чтобы модель не застревала на одних и тех же шаблонах и могла исследовать новые, более креативные ходы.
• “Train-short, generate-long”
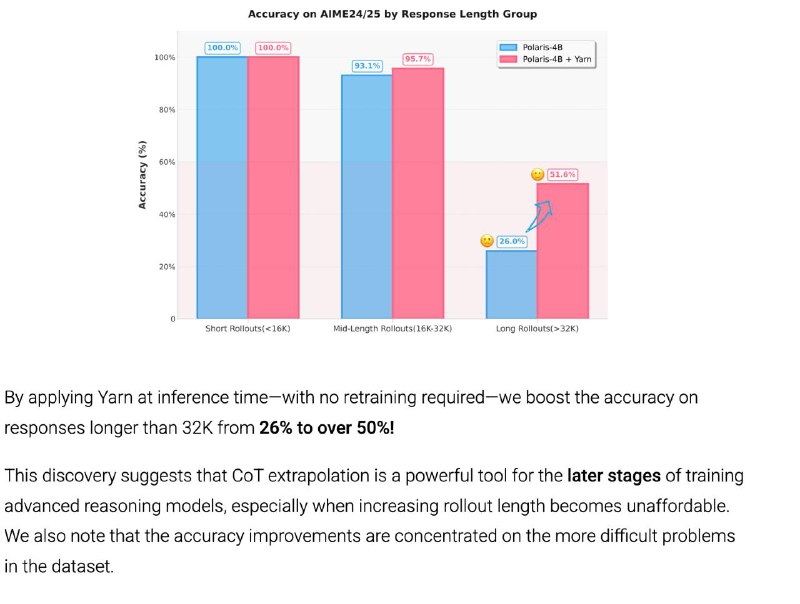
– Во время RL-обучения используем короткие цепочки рассуждений (короткие CoT) для экономии ресурсов
– На inference увеличиваем длину CoT, чтобы получить более детальные и понятные объяснения без накрутки стоимости обучения
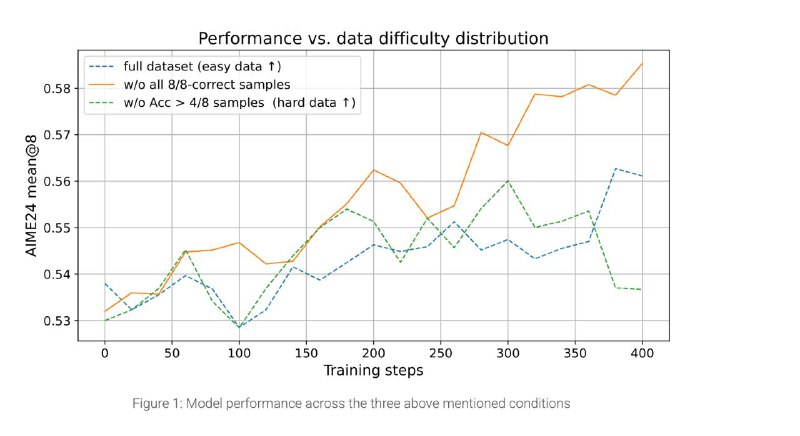
• Динамическое обновление датасета
– По мере роста точности удаляем примеры с accuracy > 90 %, чтобы не «портить» модель слишком лёгкими задачами
– Поддерживаем постоянный вызов модели на её пределе возможностей
• Улучшенная reward-функция
– Комбинируем стандартный RL-reward с бонусами за разнообразие и глубину рассуждений
– Это позволяет модели учиться не только давать правильный ответ, но и объяснять логику своих решений
Преимущества Polaris
• Благодаря Polaris даже компактные LLM (4 B и 7 B) достигают и даже «тяжеловесов» (32 B–235 B) на AIME, MATH и GPQA
• Обучение на доступных GPU уровня consumer-grade — до 10× экономии ресурсов и затрат по сравнению с традиционными RL-пайплайнами
• Полный открытый стек: исходники, подборка данных и веса
• Простота и модульность: готовый к использованию фреймворк для быстрого внедрения и масштабирования без дорогостоящей инфраструктуры
Polaris доказывает, что качество данных и грамотная настройка RL-процесса важнее просто «больших моделей». С ним вы получите продвинутую reasoning-LLM, которую можно запустить локально и масштабировать везде, где есть обычная GPU.
▪Blog post: https://hkunlp.github.io/blog/2025/Polaris
▪Model: https://huggingface.co/POLARIS-Project
▪Code: https://github.com/ChenxinAn-fdu/POLARIS
▪Notion: https://honorable-payment-890.notion.site/POLARIS-A-POst-training-recipe-for-scaling-reinforcement-Learning-on-Advanced-ReasonIng-modelS-1dfa954ff7c38094923ec7772bf447a1
@ai_machinelearning_big_data
#ml #ai • #Polaris #PostTraining #ReinforcementLearning #LLM
Polaris — это набор простых, но мощных приёмов, который позволяет даже компактным LLM (4 B, 7 B) догнать и превзойти «тяжеловесов» на задачах рассуждения (открытая 4B модель превосходи Claude-4-Opus).
Вот как это работает и почему важно:
• Управление сложностью данных
– Генерируем несколько (например, 8) вариантов решения от базовой модели
– Оцениваем, какие примеры слишком простые (8/8) или слишком сложные (0/8), и убираем их
– Оставляем «умеренные» задачи с правильными решениями в 20–80 % случаев, чтобы быть ни слишком лёгкими, ни слишком сложными
• Разнообразие «прогонов» (rollout-ов)
– Мы запускаем модель несколько раз на одной и той же задаче и смотрим, как меняются её рассуждения: одни и те же входные данные, но разные «пути» к решению.
– Считаем, насколько разнообразны эти пути (т. е. их «энтропия»): если модели всё время идут по одной линии, новых идей не появляется; если слишком хаотично — рассуждения неустойчивы.
– Задаём начальную “температуру” генерации там, где баланс между стабильностью и разнообразием оптимален, а затем постепенно её повышаем, чтобы модель не застревала на одних и тех же шаблонах и могла исследовать новые, более креативные ходы.
• “Train-short, generate-long”
– Во время RL-обучения используем короткие цепочки рассуждений (короткие CoT) для экономии ресурсов
– На inference увеличиваем длину CoT, чтобы получить более детальные и понятные объяснения без накрутки стоимости обучения
• Динамическое обновление датасета
– По мере роста точности удаляем примеры с accuracy > 90 %, чтобы не «портить» модель слишком лёгкими задачами
– Поддерживаем постоянный вызов модели на её пределе возможностей
• Улучшенная reward-функция
– Комбинируем стандартный RL-reward с бонусами за разнообразие и глубину рассуждений
– Это позволяет модели учиться не только давать правильный ответ, но и объяснять логику своих решений
Преимущества Polaris
• Благодаря Polaris даже компактные LLM (4 B и 7 B) достигают и даже «тяжеловесов» (32 B–235 B) на AIME, MATH и GPQA
• Обучение на доступных GPU уровня consumer-grade — до 10× экономии ресурсов и затрат по сравнению с традиционными RL-пайплайнами
• Полный открытый стек: исходники, подборка данных и веса
• Простота и модульность: готовый к использованию фреймворк для быстрого внедрения и масштабирования без дорогостоящей инфраструктуры
Polaris доказывает, что качество данных и грамотная настройка RL-процесса важнее просто «больших моделей». С ним вы получите продвинутую reasoning-LLM, которую можно запустить локально и масштабировать везде, где есть обычная GPU.
▪Blog post: https://hkunlp.github.io/blog/2025/Polaris
▪Model: https://huggingface.co/POLARIS-Project
▪Code: https://github.com/ChenxinAn-fdu/POLARIS
▪Notion: https://honorable-payment-890.notion.site/POLARIS-A-POst-training-recipe-for-scaling-reinforcement-Learning-on-Advanced-ReasonIng-modelS-1dfa954ff7c38094923ec7772bf447a1
@ai_machinelearning_big_data
#ml #ai • #Polaris #PostTraining #ReinforcementLearning #LLM
tg-me.com/sqlhub/1936
Create:
Last Update:
Last Update:
🚀 Парадигма меняется: Polaris выводит локальные модели на новый уровень
Polaris — это набор простых, но мощных приёмов, который позволяет даже компактным LLM (4 B, 7 B) догнать и превзойти «тяжеловесов» на задачах рассуждения (открытая 4B модель превосходи Claude-4-Opus).
Вот как это работает и почему важно:
• Управление сложностью данных
– Генерируем несколько (например, 8) вариантов решения от базовой модели
– Оцениваем, какие примеры слишком простые (8/8) или слишком сложные (0/8), и убираем их
– Оставляем «умеренные» задачи с правильными решениями в 20–80 % случаев, чтобы быть ни слишком лёгкими, ни слишком сложными
• Разнообразие «прогонов» (rollout-ов)
– Мы запускаем модель несколько раз на одной и той же задаче и смотрим, как меняются её рассуждения: одни и те же входные данные, но разные «пути» к решению.
– Считаем, насколько разнообразны эти пути (т. е. их «энтропия»): если модели всё время идут по одной линии, новых идей не появляется; если слишком хаотично — рассуждения неустойчивы.
– Задаём начальную “температуру” генерации там, где баланс между стабильностью и разнообразием оптимален, а затем постепенно её повышаем, чтобы модель не застревала на одних и тех же шаблонах и могла исследовать новые, более креативные ходы.
• “Train-short, generate-long”
– Во время RL-обучения используем короткие цепочки рассуждений (короткие CoT) для экономии ресурсов
– На inference увеличиваем длину CoT, чтобы получить более детальные и понятные объяснения без накрутки стоимости обучения
• Динамическое обновление датасета
– По мере роста точности удаляем примеры с accuracy > 90 %, чтобы не «портить» модель слишком лёгкими задачами
– Поддерживаем постоянный вызов модели на её пределе возможностей
• Улучшенная reward-функция
– Комбинируем стандартный RL-reward с бонусами за разнообразие и глубину рассуждений
– Это позволяет модели учиться не только давать правильный ответ, но и объяснять логику своих решений
Преимущества Polaris
• Благодаря Polaris даже компактные LLM (4 B и 7 B) достигают и даже «тяжеловесов» (32 B–235 B) на AIME, MATH и GPQA
• Обучение на доступных GPU уровня consumer-grade — до 10× экономии ресурсов и затрат по сравнению с традиционными RL-пайплайнами
• Полный открытый стек: исходники, подборка данных и веса
• Простота и модульность: готовый к использованию фреймворк для быстрого внедрения и масштабирования без дорогостоящей инфраструктуры
Polaris доказывает, что качество данных и грамотная настройка RL-процесса важнее просто «больших моделей». С ним вы получите продвинутую reasoning-LLM, которую можно запустить локально и масштабировать везде, где есть обычная GPU.
▪Blog post: https://hkunlp.github.io/blog/2025/Polaris
▪Model: https://huggingface.co/POLARIS-Project
▪Code: https://github.com/ChenxinAn-fdu/POLARIS
▪Notion: https://honorable-payment-890.notion.site/POLARIS-A-POst-training-recipe-for-scaling-reinforcement-Learning-on-Advanced-ReasonIng-modelS-1dfa954ff7c38094923ec7772bf447a1
@ai_machinelearning_big_data
#ml #ai • #Polaris #PostTraining #ReinforcementLearning #LLM
Polaris — это набор простых, но мощных приёмов, который позволяет даже компактным LLM (4 B, 7 B) догнать и превзойти «тяжеловесов» на задачах рассуждения (открытая 4B модель превосходи Claude-4-Opus).
Вот как это работает и почему важно:
• Управление сложностью данных
– Генерируем несколько (например, 8) вариантов решения от базовой модели
– Оцениваем, какие примеры слишком простые (8/8) или слишком сложные (0/8), и убираем их
– Оставляем «умеренные» задачи с правильными решениями в 20–80 % случаев, чтобы быть ни слишком лёгкими, ни слишком сложными
• Разнообразие «прогонов» (rollout-ов)
– Мы запускаем модель несколько раз на одной и той же задаче и смотрим, как меняются её рассуждения: одни и те же входные данные, но разные «пути» к решению.
– Считаем, насколько разнообразны эти пути (т. е. их «энтропия»): если модели всё время идут по одной линии, новых идей не появляется; если слишком хаотично — рассуждения неустойчивы.
– Задаём начальную “температуру” генерации там, где баланс между стабильностью и разнообразием оптимален, а затем постепенно её повышаем, чтобы модель не застревала на одних и тех же шаблонах и могла исследовать новые, более креативные ходы.
• “Train-short, generate-long”
– Во время RL-обучения используем короткие цепочки рассуждений (короткие CoT) для экономии ресурсов
– На inference увеличиваем длину CoT, чтобы получить более детальные и понятные объяснения без накрутки стоимости обучения
• Динамическое обновление датасета
– По мере роста точности удаляем примеры с accuracy > 90 %, чтобы не «портить» модель слишком лёгкими задачами
– Поддерживаем постоянный вызов модели на её пределе возможностей
• Улучшенная reward-функция
– Комбинируем стандартный RL-reward с бонусами за разнообразие и глубину рассуждений
– Это позволяет модели учиться не только давать правильный ответ, но и объяснять логику своих решений
Преимущества Polaris
• Благодаря Polaris даже компактные LLM (4 B и 7 B) достигают и даже «тяжеловесов» (32 B–235 B) на AIME, MATH и GPQA
• Обучение на доступных GPU уровня consumer-grade — до 10× экономии ресурсов и затрат по сравнению с традиционными RL-пайплайнами
• Полный открытый стек: исходники, подборка данных и веса
• Простота и модульность: готовый к использованию фреймворк для быстрого внедрения и масштабирования без дорогостоящей инфраструктуры
Polaris доказывает, что качество данных и грамотная настройка RL-процесса важнее просто «больших моделей». С ним вы получите продвинутую reasoning-LLM, которую можно запустить локально и масштабировать везде, где есть обычная GPU.
▪Blog post: https://hkunlp.github.io/blog/2025/Polaris
▪Model: https://huggingface.co/POLARIS-Project
▪Code: https://github.com/ChenxinAn-fdu/POLARIS
▪Notion: https://honorable-payment-890.notion.site/POLARIS-A-POst-training-recipe-for-scaling-reinforcement-Learning-on-Advanced-ReasonIng-modelS-1dfa954ff7c38094923ec7772bf447a1
@ai_machinelearning_big_data
#ml #ai • #Polaris #PostTraining #ReinforcementLearning #LLM
BY Data Science. SQL hub
Share with your friend now:
tg-me.com/sqlhub/1936