
tg-me.com/knowledge_accumulator/167
Last Update:
Language Agents as Optimizable Graphs [2024] - обучаем надстройку над LLM
Недавно я писал о том, что какая-то большая и сложная надстройка над LLM может дать какой-нибудь интересный результат. Нечто такое из себя представляет FunSearch, использующий LLM как генератор мутаций программ на питоне. Сегодня посмотрим на работу, в которой надстройка над LLM оптимизируется для высокой производительности на классе задач / бенчмарке. Сразу скажу - не фанат конкретно этой схемы, но направление мысли здесь задаётся неплохое.
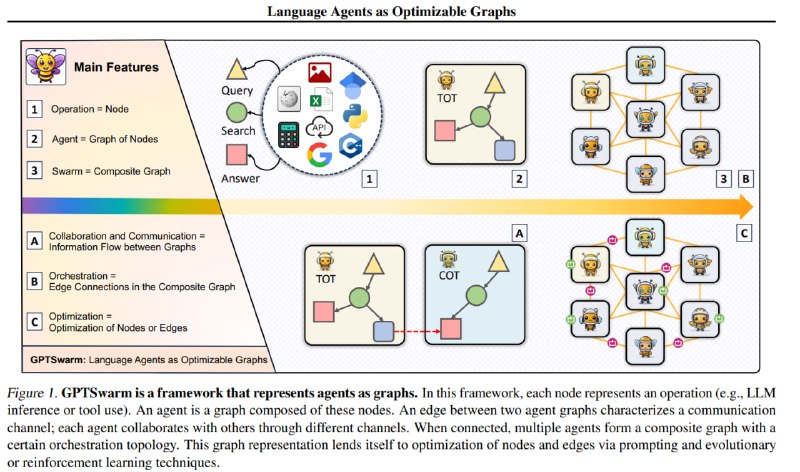
Определим языкового агента как ациклический направленный граф. В нём вершины это различные вычислительные элементы - запросы к LLM, вызовы какого-нибудь API, использование инструмента и т.д. Соединены они между собой рёбрами, обозначающими, идёт ли выход из одной вершины на вход другой. В данной статье у нас заранее задаётся множество вершин, причём у LLM-вершин есть описание того, что именно они должны делать.
Итак, мы хотели бы построить граф, набирающий как можно больше в какой-нибудь задаче, например, бенчмарке GAIA. Оптимизировать можно 2 вещи - набор рёбер и промпты каждой вершины.
1) Рёбра оптимизируем с помощью REINFORCE. Граф генерируется случайно, и вероятность каждого ребра задаётся вероятностью-параметром p. С помощью REINFORCE по этим вероятностям можно оптимизировать недифференцируемую итоговую производительность графа на задаче.
2) Промпты у вершин оптимизируется через ORPO. Для каждой вершины оптимизация независима. Это имеет смысл в данном случае, т.к. функция вершины определена заранее и подаётся на вход оптимизатору.
Графы обучаются не с нуля, их "инициализируют" какой-то известной схемой (например, несколько Tree of Thoughts) и дальше "дообучают". Нельзя сказать, что у агента есть большой простор для оптимизации, однако, это уже лучше, чем зафиксированные вручную схемы. Ждём более хитрых и гибких параметризаций такого языкового агента, в которых набор вершин тоже будет оптимизироваться, а назначение каждой отдельной вершины не будет задано заранее.
@knowledge_accumulator
BY Knowledge Accumulator
Share with your friend now:
tg-me.com/knowledge_accumulator/167