
tg-me.com/knowledge_accumulator/78
Last Update:
Adaptive Agent (AdA) [2023] - текущий флагман Meta-RL
Сегодня расскажу вам о работе от Deepmind, применяющий описанную выше логику в современном масштабе.
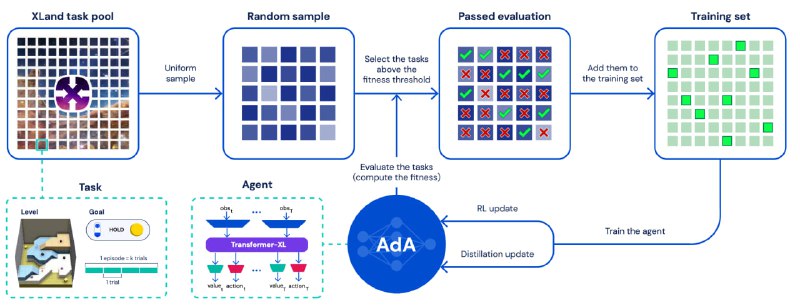
1) В качестве задачи используется Xland 2.0 - это семейство из 10^40 задач. Это случайно генерируемые 3D-"площадки" со каким-то набором объектов, которые можно перемещать по площадке. Агент - это "существо" на площадке с видом от первого лица, которое может физически с объектами взаимодействовать. Объекты так же могут взаимодействовать в другими объектами согласно каким-то правилам (например, объект №1 и №4 при касании друг с другом исчезают / превращаются в объект №5). Агенту назначается награда за какое-то событие в этой среде (например, агент держит в руках объект №2).
2) В качестве модели используется полумиллиардный трансформер, который принимает на вход последние N событий из своей истории - вид от первого лица, награды и другую информацию. Как я уже говорил в прошлом посте, в постановке мета-обучения границы между эпизодами в одной задаче стёрты. Обучение занимает десятки миллиардов шагов.
3) Одним из ключей к успеху является Auto-curriculum learning. Мы регулярно сэмплируем пачку новых задач для обучения, но не учимся на всех подряд. Мы выбираем те задачи, которые для нас оптимальные по сложности - не слишком простые и не слишком сложные.
В результате у системы получается значительно обходить человека на Xland-задачах. При этом на графиках видно, что система умеет именно адаптироваться к новым задачам - производительность значительно растёт с каждой попыткой, и где-то на 10 попытке доходит до плато.
На мой взгляд, это очень интересное направление исследований. Однако, стоит заметить, что эти Xland-задачи не требуют интеллектуального поведения агентов, а ресурсов для обучения уже требуется столько, сколько в принципе сейчас способно на такое выделить человечество. Так что дальнейшее масштабирование втупую вряд ли даст нам огромное плоды. Будет очень интересно следить за дальнейшим развитием.
Видеообзор на полчаса.
@knowledge_accumulator
BY Knowledge Accumulator
Share with your friend now:
tg-me.com/knowledge_accumulator/78