tg-me.com/ai_machinelearning_big_data/7789
Last Update:
SEAL - это методика от MiT, позволяющая LLM самостоятельно генерировать обучающие данные и настраивать параметры обучения, чтобы адаптироваться к новым задачам. Вместо традиционного файнтюна на внешних данных модель учится рефлексировать: анализировать контекст, создавать из него синтетические данные и применять их для корректировки собственных весов через механизм усиленного обучения.
SEAL, по сути, это два разделенных цикла:
Этот процесс повторяется, постепенно формируя у модели навык преобразования исходных данных в полезные обучающие сигналы.
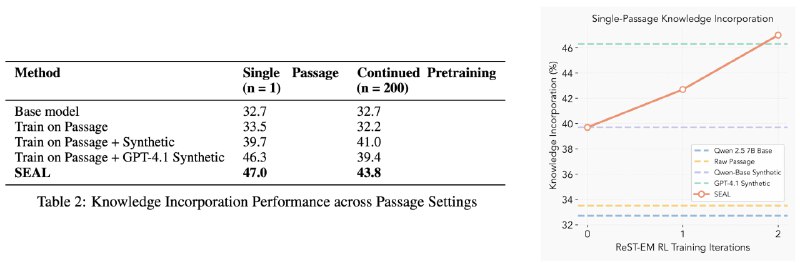
SEAL протестили на 2 задачах: интеграции новых знаний и few-shot обучении. В первом случае модель генерирует логические следствия из текста, дообучается на них и улучшает точность ответов на вопросы без доступа к исходному тексту.
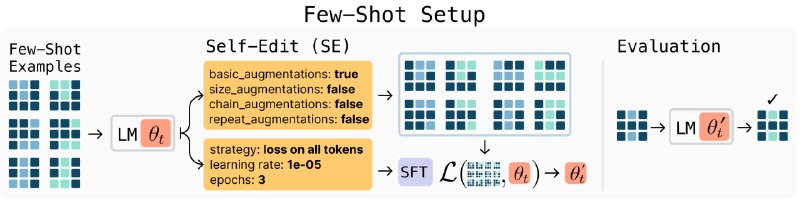
Во втором случае SEAL выбирает оптимальные аугментации данных и гиперпараметры для обучения на примерах задач ARC-AGI.
В обоих сценариях SEAL превзошел подходы с фиксированными шаблонами (ICL, TTT+Self Edit без RL и) и даже синтетическими данными от GPT-4.1.
Метод скорее академический и по большей части экспериментальный, у него есть ограничения:
@ai_machinelearning_big_data
#AI #ML #LLM #SEAL #RL #MiT