Есть ряд методов машинного обучения, которым раньше иногда посвящали в курсах целую лекцию, в учебниках целую главу, и вообще относились с большой серьезностью. Сейчас же ситуация немного поменялась, потому что из классических (не deep learning) методов как правило используются или линейные модели (когда нужна интерпретируемость или легкость настройки и выкатки в продакшн, либо когда признаки разреженные, либо когда известно, что зависимость с какой-то точностью можно считать линейной, либо когда мало данных и нет доводов в пользу какого-то другого вида модели) или градиентный бустинг над деревьями (примерно во всех остальных случаях).
Уже лет пять или даже больше я, когда веду курсы машинного обучения, выхожу из положения следующим образом: рассказ про «простые методы» при всем их разнообразии помещается в начале курса в одно занятие, чтобы дать некоторый исторический экскурс и уберечь слушателей от самостоятельного «изобретения» этих методов с последующими большими надеждами, что «ух сейчас как заработает!». Во вторую очередь я отдаю дань истории, потому что не знаю, к кому слушатели однажды попадут на собеседование. Вдруг там будет какой-то любитель наивного байесовского классификатора или kNN, который откажет кандидату просто по принципу «если он такие простые вещи не знает, то о чем с ним говорить». Далее я приведу небольшое описание этих «простых алгоритмов», и чем они еще могут пригодиться в 2024 году.
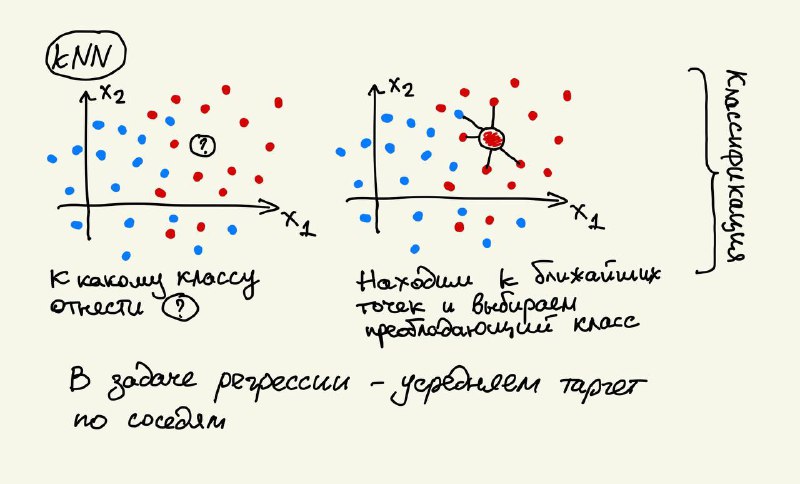
Метод k ближайших соседей Идея метода проста до ужаса: чтобы классифицировать объект выборки, найдем k объектов, похожих на него, и ответим тем классом, который среди них больше представлен. Хотим решить задачу регрессии (спрогнозировать число)? Без проблем, также найдем k ближайших объектов и усредним правильные ответы по ним. Ну например, если хотим понять, сколько заработает магазин в новой локации, находим k похожих на него и просто усредняем их продажи. Вот такой вот простой прогноз. Только когда говорят "ближайшие соседи" имеют ввиду именно в пространстве признаков, т.е. прогнозировать продажи в новом магазине надо не по географически ближайшим, а по тем, у которых похожий полный набор параметр: распределение доходов клиентов вокруг локации, количество своих магазинов и магазинов конкурентов рядом, размер города и т.д.
Если продажи в новом магазине сейчас вряд ли кто-то серьезно прогнозирует с помощью kNN, то вот в персональных рекомендациях метод k ближайших соседей до сих пор остается бейзлайном, и хорошо если всякие матричные разложения, бустинги и нейросетки его превосходят по качеству. Гораздо забавнее, если нет, потому что не сравнивали 🙂
Кроме того, kNN это достаточно широкое множество алгоритмов в том смысле, что есть какие параметры покрутить. Можно взвешивать и преобразовывать признаки, можно назначать разные веса соседям, можно применять всякие Kernel-based методы, в общем при желании есть куда закопаться, а это мы еще не вспомнили про быстрый поиск соседей в N-мерном пространстве признаков и всякие там ANN (Approximate Nearest Neighbors). В общем те, кто любят kNN, найдут чем занять и лекцию, и главу, и даже целый учебник.
Есть ряд методов машинного обучения, которым раньше иногда посвящали в курсах целую лекцию, в учебниках целую главу, и вообще относились с большой серьезностью. Сейчас же ситуация немного поменялась, потому что из классических (не deep learning) методов как правило используются или линейные модели (когда нужна интерпретируемость или легкость настройки и выкатки в продакшн, либо когда признаки разреженные, либо когда известно, что зависимость с какой-то точностью можно считать линейной, либо когда мало данных и нет доводов в пользу какого-то другого вида модели) или градиентный бустинг над деревьями (примерно во всех остальных случаях).
Уже лет пять или даже больше я, когда веду курсы машинного обучения, выхожу из положения следующим образом: рассказ про «простые методы» при всем их разнообразии помещается в начале курса в одно занятие, чтобы дать некоторый исторический экскурс и уберечь слушателей от самостоятельного «изобретения» этих методов с последующими большими надеждами, что «ух сейчас как заработает!». Во вторую очередь я отдаю дань истории, потому что не знаю, к кому слушатели однажды попадут на собеседование. Вдруг там будет какой-то любитель наивного байесовского классификатора или kNN, который откажет кандидату просто по принципу «если он такие простые вещи не знает, то о чем с ним говорить». Далее я приведу небольшое описание этих «простых алгоритмов», и чем они еще могут пригодиться в 2024 году.
Метод k ближайших соседей Идея метода проста до ужаса: чтобы классифицировать объект выборки, найдем k объектов, похожих на него, и ответим тем классом, который среди них больше представлен. Хотим решить задачу регрессии (спрогнозировать число)? Без проблем, также найдем k ближайших объектов и усредним правильные ответы по ним. Ну например, если хотим понять, сколько заработает магазин в новой локации, находим k похожих на него и просто усредняем их продажи. Вот такой вот простой прогноз. Только когда говорят "ближайшие соседи" имеют ввиду именно в пространстве признаков, т.е. прогнозировать продажи в новом магазине надо не по географически ближайшим, а по тем, у которых похожий полный набор параметр: распределение доходов клиентов вокруг локации, количество своих магазинов и магазинов конкурентов рядом, размер города и т.д.
Если продажи в новом магазине сейчас вряд ли кто-то серьезно прогнозирует с помощью kNN, то вот в персональных рекомендациях метод k ближайших соседей до сих пор остается бейзлайном, и хорошо если всякие матричные разложения, бустинги и нейросетки его превосходят по качеству. Гораздо забавнее, если нет, потому что не сравнивали 🙂
Кроме того, kNN это достаточно широкое множество алгоритмов в том смысле, что есть какие параметры покрутить. Можно взвешивать и преобразовывать признаки, можно назначать разные веса соседям, можно применять всякие Kernel-based методы, в общем при желании есть куда закопаться, а это мы еще не вспомнили про быстрый поиск соседей в N-мерном пространстве признаков и всякие там ANN (Approximate Nearest Neighbors). В общем те, кто любят kNN, найдут чем занять и лекцию, и главу, и даже целый учебник.
Telegram is a cloud-based instant messaging service that has been making rounds as a popular option for those who wish to keep their messages secure. Telegram boasts a collection of different features, but it’s best known for its ability to secure messages and media by encrypting them during transit; this prevents third-parties from snooping on messages easily. Let’s take a look at what Telegram can do and why you might want to use it.
Telegram announces Search Filters
With the help of the Search Filters option, users can now filter search results by type. They can do that by using the new tabs: Media, Links, Files and others. Searches can be done based on the particular time period like by typing in the date or even “Yesterday”. If users type in the name of a person, group, channel or bot, an extra filter will be applied to the searches.