Warning: file_put_contents(aCache/aDaily/post/knowledge_accumulator/-34" target="_blank" rel="noopener" onclick="return confirm('Open this link?\n\n'+this.href);">AlphaZero</a> выходит из плена настольных игр<br/><br/>Попытка моделировать динамику среды (то, какими состояние и награда у среды будут следующими, если знаем текущее состояние и действие агента) - это отдельная песня в <a href="https://t.me/knowledge_accumulator/16" target="_blank" rel="noopener" onclick="return confirm('Open this link?\n\n'+this.href);">рамках RL</a>, которая обычно не даёт такого профита, который позволяет <a href="https://t.me/knowledge_accumulator/9" target="_blank" rel="noopener" onclick="return confirm('Open this link?\n\n'+this.href);">компенсировать сложность подхода</a>. Всё потому, что генерировать состояния слишком трудно из-за неопределённости в среде и высокой размерности состояния.<br/><br/>Тем не менее, в рамках MuZero пытаются применить подход к выбору действий с помощью планирования, как в <a href="https://t.me/knowledge_accumulator/34" target="_blank" rel="noopener" onclick="return confirm('Open this link?\n\n'+this.href);">AlphaZero</a>, в ситуации, когда доступа к модели среды нет.<br/><br/>Что делают с проблемой сложности среды? Оказывается, можно просто <u>забить на состояния</u>, и при обучении своей модели динамики среды пытаться предсказывать только будущие награды и действия нашей стратегии. Ведь чтобы их предсказывать, нужно извлечь всё самое полезное из динамики и не более. Удивительно, но это работает! Более того, эта система может играть в Го на уровне AlphaZero, у которой доступ к модели есть.<br/><br/>Я думаю, что отказ от попытки предсказывать будущее состояние это верно, потому что убирает ненужную сложность. От этого отказались в <a href="https://t.me/knowledge_accumulator/22" target="_blank" rel="noopener" onclick="return confirm('Open this link?\n\n'+this.href);">RND</a>, <a href="https://t.me/knowledge_accumulator/26-): Failed to open stream: No such file or directory in /var/www/tg-me/post.php on line 50 Knowledge Accumulator | Telegram Webview: knowledge_accumulator/35 -
Попытка моделировать динамику среды (то, какими состояние и награда у среды будут следующими, если знаем текущее состояние и действие агента) - это отдельная песня в рамках RL, которая обычно не даёт такого профита, который позволяет компенсировать сложность подхода. Всё потому, что генерировать состояния слишком трудно из-за неопределённости в среде и высокой размерности состояния.
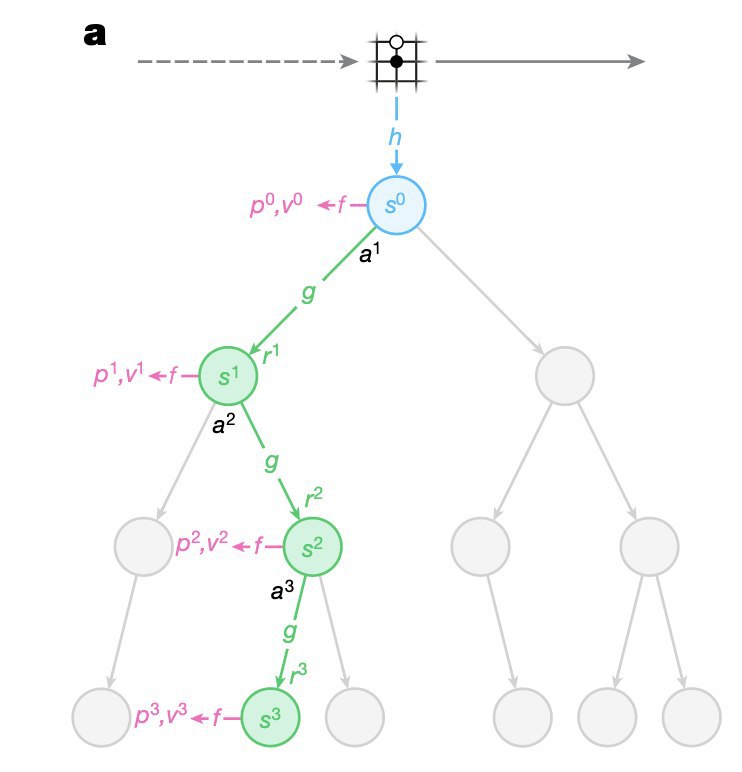
Тем не менее, в рамках MuZero пытаются применить подход к выбору действий с помощью планирования, как в AlphaZero, в ситуации, когда доступа к модели среды нет.
Что делают с проблемой сложности среды? Оказывается, можно просто забить на состояния, и при обучении своей модели динамики среды пытаться предсказывать только будущие награды и действия нашей стратегии. Ведь чтобы их предсказывать, нужно извлечь всё самое полезное из динамики и не более. Удивительно, но это работает! Более того, эта система может играть в Го на уровне AlphaZero, у которой доступ к модели есть.
Я думаю, что отказ от попытки предсказывать будущее состояние это верно, потому что убирает ненужную сложность. От этого отказались в RND, NGU, в MuZero и не только. Глобально говоря, от этого имеет смысл отказываться всегда, когда генерация не является самоцелью. И я думаю, что это рано или поздно будут делать во всех доменах, даже в текстах.
Попытка моделировать динамику среды (то, какими состояние и награда у среды будут следующими, если знаем текущее состояние и действие агента) - это отдельная песня в рамках RL, которая обычно не даёт такого профита, который позволяет компенсировать сложность подхода. Всё потому, что генерировать состояния слишком трудно из-за неопределённости в среде и высокой размерности состояния.
Тем не менее, в рамках MuZero пытаются применить подход к выбору действий с помощью планирования, как в AlphaZero, в ситуации, когда доступа к модели среды нет.
Что делают с проблемой сложности среды? Оказывается, можно просто забить на состояния, и при обучении своей модели динамики среды пытаться предсказывать только будущие награды и действия нашей стратегии. Ведь чтобы их предсказывать, нужно извлечь всё самое полезное из динамики и не более. Удивительно, но это работает! Более того, эта система может играть в Го на уровне AlphaZero, у которой доступ к модели есть.
Я думаю, что отказ от попытки предсказывать будущее состояние это верно, потому что убирает ненужную сложность. От этого отказались в RND, NGU, в MuZero и не только. Глобально говоря, от этого имеет смысл отказываться всегда, когда генерация не является самоцелью. И я думаю, что это рано или поздно будут делать во всех доменах, даже в текстах.
You can’t. What you can do, though, is use WhatsApp’s and Telegram’s web platforms to transfer stickers. It’s easy, but might take a while.Open WhatsApp in your browser, find a sticker you like in a chat, and right-click on it to save it as an image. The file won’t be a picture, though—it’s a webpage and will have a .webp extension. Don’t be scared, this is the way. Repeat this step to save as many stickers as you want.Then, open Telegram in your browser and go into your Saved messages chat. Just as you’d share a file with a friend, click the Share file button on the bottom left of the chat window (it looks like a dog-eared paper), and select the .webp files you downloaded. Click Open and you’ll see your stickers in your Saved messages chat. This is now your sticker depository. To use them, forward them as you would a message from one chat to the other: by clicking or long-pressing on the sticker, and then choosing Forward.
Newly uncovered hack campaign in Telegram
The campaign, which security firm Check Point has named Rampant Kitten, comprises two main components, one for Windows and the other for Android. Rampant Kitten’s objective is to steal Telegram messages, passwords, and two-factor authentication codes sent by SMS and then also take screenshots and record sounds within earshot of an infected phone, the researchers said in a post published on Friday.