
tg-me.com/llm_under_hood/481
Last Update:
Кейс - поиск ошибок в строительных заказах на покупку
Давно не было разборов кейсов. Давайте расскажу про один из текущих. Он тоже реализуется по концепции LLM Core.
Команда кейса участвует в соревновании за право реализовать проект для строительной компании. Компания высылает своим подрядчикам заказы на покупку, получает от них ответные предложения, а потом перепроверяет, что фактические параметры заказа не нарушены. Для этого нужно извлекать данные из многостраничных PDF-ок в форматах разных поставщиков.
Этот проект - обычный data extraction на базе VLM, но есть три нюанса:
(1) Реализовать надо в Google, а у Gemini на Vertex AI пока очень упоротый structured output format (не JSON schema, а Vertex AI API)
(2) Клиент очень медленный. Пачки PDF-ок он прислал, а вот ground truth дата - нет. Ибо организационные пробуксовки помноженные на рождественнские праздники.
(3) Конкуренты хотят использовать Google Document AI и обучать какие-то дополнительные модели. Если сделать надежное решение просто на 1-2 промптах, то команда может хорошо выделиться.
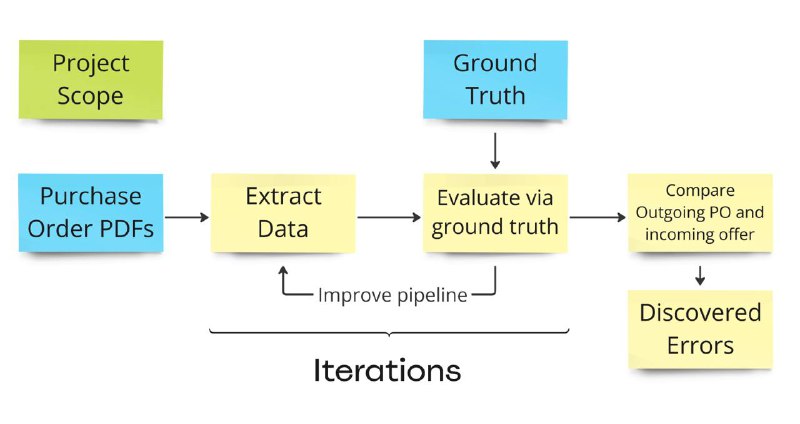
Про детали реализации не буду углубляться, это обычный structured data extraction, как в победителе Enterprise RAG Challenge или кейсе про захват рынка. Из особенностей реализации в этом проекте:
(1) да, нужно возиться с SO форматом на Gemini Pro под Vertex AI, но это решаемая проблема.
(2) отсутствие ground truth data - тоже решаемая проблема. Можно взять другую модель от другого поставщика (например, Claude 3.5 Sonnet v2) и сравнивать ответы разных моделей. Если они сошлись, то обе модели извлекают правильно. Если расходятся, то одна из черепашек – ошибается. Строим heatmap, чтобы понять масштаб проблем и пойти улучшать.
(3) то, что в данном проекте извлечение данных из PDF - это implementation detail. И Gemini и Sonnet по API принимают на вход PDF.
(4) обе модели начинают путаться, когда за раз хочется извлечь заказ на покупку на 20-30 позиций со всеми данными. Разбивка процесса извлечения на два промпта повышает качество. Но есть теория, что нормальный CoT поможет стабильно извлекать одним единственным промптом.
И еще тут возникает интересный момент с тестированием. Команда проекта бралась за него зная, что может быть проблема с получением ground truth data для тестов. А без тестов обычно браться за LLM проекты - я считаю слишком рискованным.
Но в этом проекте сразу было понятно, какие блоки можно тестировать и как (а это не всегда так). Плюс было видно, что можно временно заменить ground truth данные сравнением результатов двух моделей. А это уже позволяет запустить стабильный и контроллируемый цикл разработки. Потом можно будет либо вручную разметить часть PDF либо получить исходные данные из БД.
Во вторых, в проекте есть аж две очевидных точки для тестирования внутренних блоков - тест на извлечение PDF-ок и тест на результаты работы всего pipeline (что в такой-то PDF-ке есть такие-то ошибки).
Добавление нескольких точек тестирования сильно снижает риски реализации данного проекта. Поэтому его можно было брать.
А как вы тестируете свои проекты с LLM под капотом? И что делаете, если удобных данных для тестирования нет?
Ваш, @llm_under_hood 🤗
BY LLM под капотом
Share with your friend now:
tg-me.com/llm_under_hood/481