tg-me.com/ai_machinelearning_big_data/7292
Last Update:
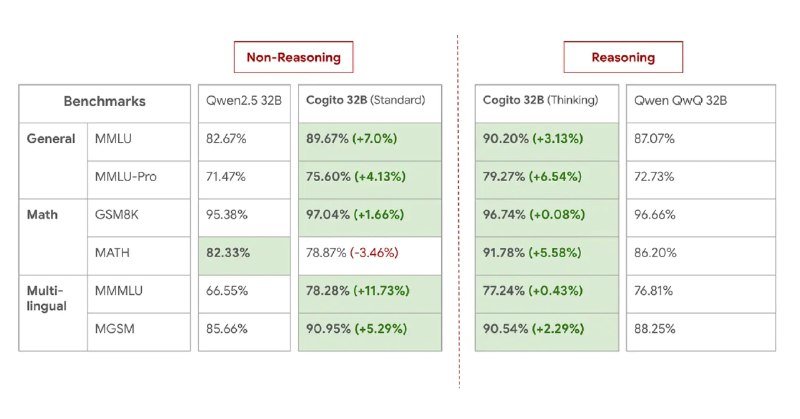
Deep Cogito выпустила семейство языковых моделей размером 3B, 8B, 14B, 32B и 70B параметров, которые уже доступны для загрузки.
По заявлению разработчиков, их модели превосходят аналогичные открытые решения от LLaMA, DeepSeek и Qwen в большинстве стандартных бенчмарков. Например, 70B-версия обходит новую 109B MoE-модель Llama 4, несмотря на меньший размер.
Все модели обучены с помощью метода Iterated Distillation and Amplification (IDA) — стратегии, которая сочетает итеративное самоулучшение и «сжатие» интеллекта для преодоления ограничений, накладываемых человеческим контролем.
Суть IDA проста: сначала модель «усиливает» свои способности, тратя больше вычислительных ресурсов на поиск решений через CoT, а затем «дистиллирует» эти улучшения в свои параметры. Такой цикл повторяется, создавая петлю обратной связи — каждая итерация делает модель умнее, а её мышление эффективнее. По словам команды, этот подход не только масштабируем, но и быстрее, чем RLHF.
Семейство поддерживает 2 режима работы: стандартный (прямой ответ) и «рефлексивный», где система сначала обдумывает запрос, как это реализовано в Claude 3.7. Они оптимизированы для программирования, вызова функций и агентских сценариев, но без акцента на CoT — разработчики считают, что короткие шаги эффективнее в реальных задачах.
Уже в ближайшие месяцы ожидаются версии на 109B, 400B и 671B параметров и вариации с MoE-архитектурой.
Модели доступны на Hugging Face, Ollama и через API Fireworks AI/Together AI.
@ai_machinelearning_big_data