tg-me.com/ai_machinelearning_big_data/7632
Create:
Last Update:
Last Update:
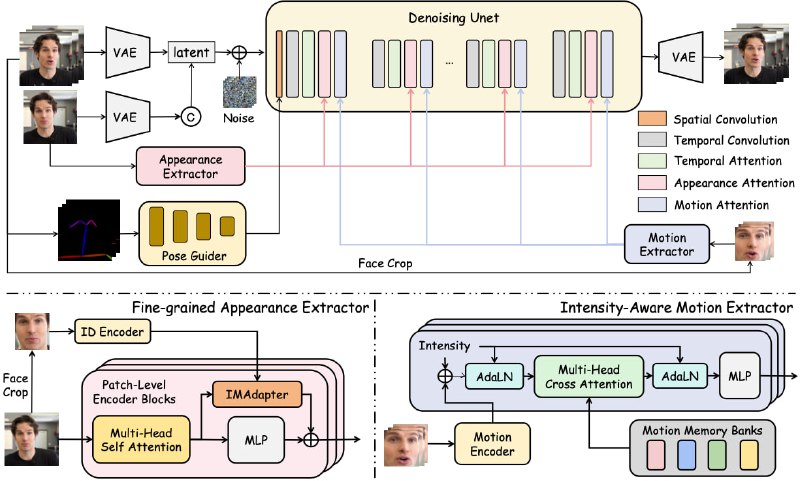
Спустя чуть больше двух месяцев, Tencent опубликовала веса и код инференса проекта HunyuanPortrait - системы на основе диффузионных моделей для создания реалистичных анимированных портретов.
На вход подается видео, с которого движения переносятся на целевое изображение для "оживления". Режима "тext-to-motion", судя по всему - нет.
Под капотом - набор моделей на основе SVD, DiNOv2, Arc2Face и YoloFace.
Разработчики уверяют, что инференс заводится на 24 Гб VRAM и их метод лучше контролирует анимацию и делает более плавные переходы между кадрами, чем существующие аналоги.
⚠️ WebUI нет, адаптации под ComfyUI - пока тоже нет.
# Clone repo
git clone https://github.com/Tencent-Hunyuan/HunyuanPortrait
# Install requirements
pip3 install torch torchvision torchaudio
pip3 install -r requirements.txt
# Run
video_path="your_video.mp4"
image_path="your_image.png"
python inference.py \
--config config/hunyuan-portrait.yaml \
--video_path $video_path \
--image_path $image_path
@ai_machinelearning_big_data
#AI #ML #HunyuanPortrait