tg-me.com/ai_machinelearning_big_data/7813
Last Update:
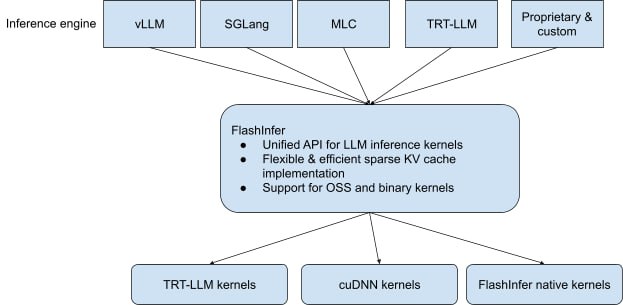
FlashInfer - это библиотека для ускорения работы с LLM, созданная NVIDIA, чтобы объединить скорость обработки на GPU и гибкость для разработчиков. Еt главная цель — сократить время вывода текста, одновременно позволяя инженерам быстро внедрять новые алгоритмы и адаптировать решения под разные задачи.
Ее архитектура спроектирована так, чтобы оставаться актуальной при появлении новых алгоритмов: будь то методы повторного использования кэша или эксперименты с форматами внимания. Плюс к этому, библиотека легковесна, она не требует установки лишних зависимостей, а ее API напоминает стандартные инструменты PyTorch.
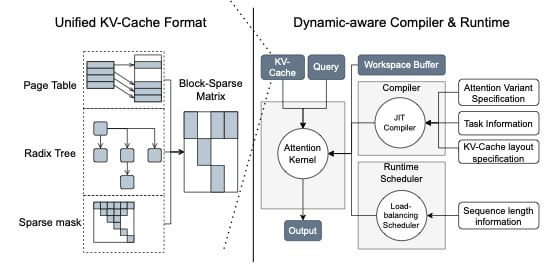
FlashInfer базируется на 2 принципах : эффективное управление памятью и динамическое планирование вычислений. Библиотека оптимизирует хранение KV-cache через блочно-разреженные структуры, уменьшая объем лишних обращений к памяти.
Это особенно важно при обработке запросов с разной длиной текста. Также используется технология JIT-компиляции, которая на лету генерирует оптимизированные CUDA-ядра под конкретную задачу.
Архитектура FlashInfer разбита на 4 модуля: Attention, GEMM, Communication и Token sampling.
FlashInfer поддерживает PyTorch через собственные операторы и DLPack API, тем самым упрощает внедрение в фреймворки vLLM и SGLang. Благодаря разделению процесса на этапы «планирования» и «запуска» библиотека минимизирует задержки: на первом шаге выбирается оптимальное ядро под параметры запроса, а затем оно переиспользуется для последующих аналогичных задач.
@ai_machinelearning_big_data
#AI #ML #LLM #FlashInfer #NVIDIA