
tg-me.com/david_random/574
Create:
Last Update:
Last Update:
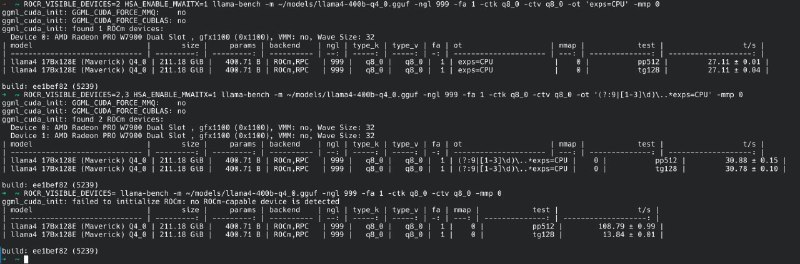
想着五一前后挑战llama4 400B发现并没什么挑战性,q4模型用7970X (150GB/s)纯CPU prefll 108 t/s decode 13.8 t/s,用8G显存offload dense层27 t/s,塞满双卡96G显存能30.8 t/s
不过llama.cpp的override tensors的prefill看起来是用纯GPU走PCIe访问内存里的模型,还有优化空间。至少不应该比纯CPU差
BY David's random thoughts
Share with your friend now:
tg-me.com/david_random/574