
tg-me.com/nodejs_lib/351
Last Update:
💡 Парсинг неструктурированных DOCX в TypeScript/Node.js: как я решил нетривиальную задачу
Недавно я взял фриланс-проект, где нужно было преобразовать «почти неструктурированные» DOCX-файлы в структурированные данные, например, в JSON. Сначала я думал, что справлюсь за пару дней. Но в итоге потратил больше пяти.
📄 Что такое «почти неструктурированные» DOCX?
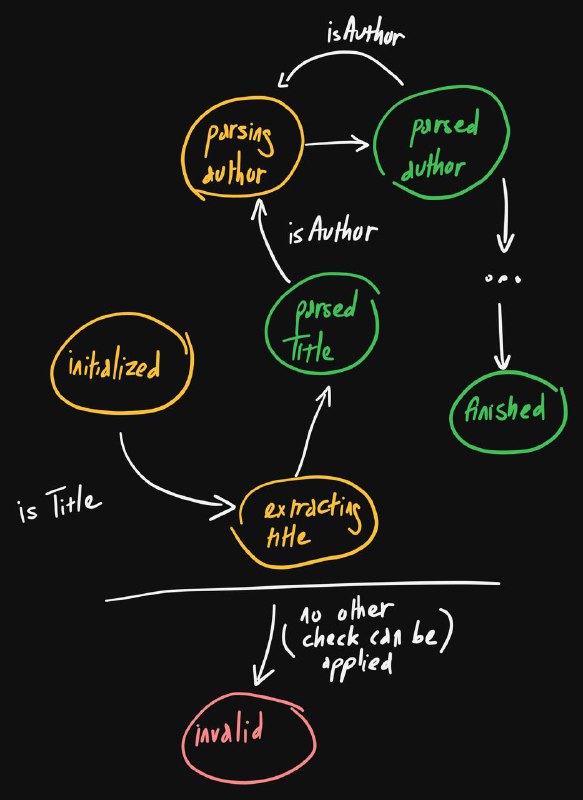
Файлы генерируются сервером и содержат несколько статей. Каждая статья обычно включает заголовок, автора, дополнительную информацию и резюме. Однако структура варьируется: где-то нет автора, где-то несколько, а вместо резюме — комментарии.
🔍 Проблемы с существующими библиотеками:
* officeparser: извлекает только текст, без структуры.
* docx4js: не имеет типов для TypeScript и сложно использовать.
* docx: больше подходит для создания DOCX, а не для парсинга.
🛠️ Моё решение:
Поняв, что DOCX — это ZIP-архив с XML-файлами, я решил сам обработать document.xml. Использовал fast-xml-parser для преобразования XML в JS-объекты. Однако структура XML оказалась сложной, и пришлось разбираться в ней вручную.
📌 Вывод:
Иногда проще написать свой парсер, чем пытаться адаптировать существующие решения. Особенно когда структура данных нестабильна и требует гибкого подхода.
https://nguyenhuythanh.com/posts/unstructured-ish-docx-parsing/
✍️ @nodejs_lib
BY Node JS
Share with your friend now:
tg-me.com/nodejs_lib/351