tg-me.com/nn_for_science/2455
Last Update:
Thinkless: LLM учится, когда нужно думать
Современные LLM, способные к долгим логическим рассуждениям продемонстрировали замечательную производительность при решении задач, требующих сложных логических выводов
Однако применение сложных рассуждений для абсолютно всех запросов часто приводит к существенной вычислительной неэффективности, особенно когда многие проблемы допускают
простые решения.
Исследователи из университета Сингапура поставили вопрос ребром: могут ли LLM научиться, когда думать?
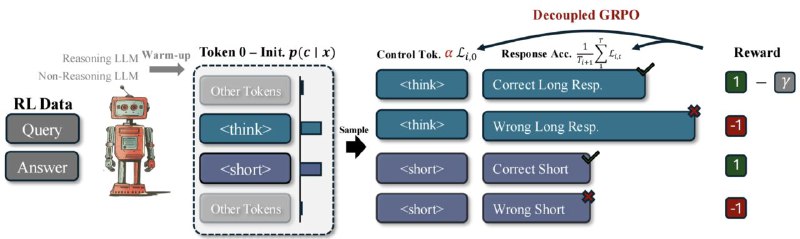
Чтобы ответить на этот вопрос, предложен Thinkless, обучаемый фрэмворк, который позволяет LLM адаптивно выбирать между краткой и длинной формой рассуждений, основываясь как на сложности задачи, так и на возможностях модели.
Thinkless обучается при помощи Reinforcement Learning, где использует два контрольных токена, <short> для кратких ответов и <think> для подробного рассуждения.
В основе предложенного метода лежит алгоритм Decoupled Group Relative Policy Optimization (DeGRPO), который разделяет выбор режима рассуждения и точности ответа, избегая коллапса.
Эмпирически, на нескольких бенчмарках, таких как Minerva Algebra, MATH-500 и GSM8K, Thinkless способен сократить использование длинных логических рассуждений на 50% - 90% без потери качества ответов.
"Думай быстро и медленно"в действии!
🧠 Статья