tg-me.com/ai_machinelearning_big_data/7714
Last Update:
Eso-LM - это новый класс языковых моделей, сочетающий автогрегрессионные (AR) и маскированные диффузионные методы (MDM), чтобы сбалансировать качество генерации и скорость работы.
Основная идея состоит в том, чтобы устранить слабые места обеих технологий: медленное выполнение AR-моделей и низкую эффективность MDM при сохранении их ключевых преимуществ - параллелизма.
Архитектура строится на гибридной функции потерь, которая одновременно обучает модель как AR-генератору, так и MDM-декодеру. Это достигается через модифицированный механизм внимания, который динамически переключается между причинным (для AR-фазы) и двусторонним (для MDM-фазы) режимами.
В отличие от классических MDM, Eso-LM использует разреженные матрицы внимания, позволяя кэшировать KV даже во время диффузионного этапа. Эта техника ощутимо сокращает вычислительную нагрузку за счет обработки только тех токенов, которые нужно «демаскировать» на каждом шаге.
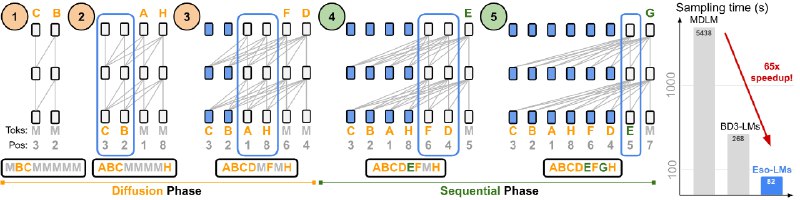
Процесс генерации разбит на 2 стадии:
Обе стадии используют единый KV-кэш, что исключает повторные вычисления и ускоряет работу в разы. В итоге, для длинных последовательностей (8192 токена), Eso-LM работает в 65 раз быстрее, чем стандартные MDM.
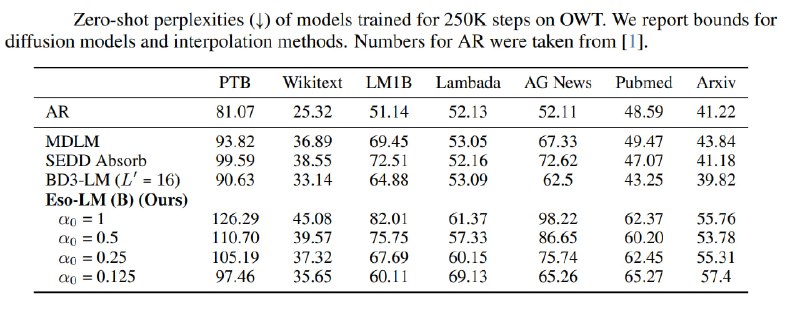
Экспериментальные модели обучали на сетах LM1B (1 млрд. слов) и OpenWebText с использованием токенизаторов BERT и GPT-2 соответственно.
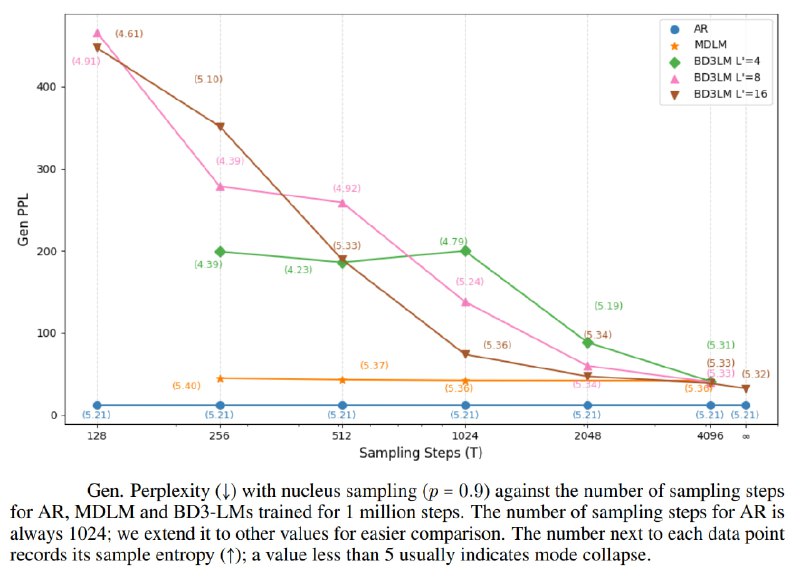
Тесты показали, что Eso-LM не только улучшает скорость, но и устраняет «модовое коллапсирование» (деградацию качества при малом числе шагов), характерное для предыдущих решений (BD3-LM).
На наборе OWT модель достигла уровня perplexity 21.87 при высокой скорости генерации, оставаясь конкурентоспособной как с MDM, так и с AR-моделями.
@ai_machinelearning_big_data
#AI #ML #LLM #EsoLM #HybridModel