tg-me.com/ai_machinelearning_big_data/7484
Last Update:
Xiaomi выпустила в опенсорсный релиз MiMo-7B — набор языковых моделей, созданных для решения сложных задач, от математики до генерации кода.
Несмотря на скромные 7 млрд. параметров, модель демонстрирует результаты, превосходящие 32B-конкурентов, разрушая стереотипы о зависимости качества от размера.
Создание MiMo началось с предтрейна на 25 трлн. токенов, где акцент был на повышении плотности логических паттернов.
Для этого разработчики пересмотрели обработку данных: улучшили извлечение математических формул и блоков кода из веб-страниц, добавили синтетические данные, сгенерированные топовыми ризонинг-моделями, и все это обработали уникальной стратегией смешивания.
На первых этапах доля STEM-контента достигала 70%, а на финальном — добавили синтетику и расширили контекст до 32K токенов.
Обучение с подкреплением на стадии посттренинга проводили на массиве из 130 тыс. задач, где каждая проверялась автоматически. Чтобы избежать reward hacking, использовали только rule-based награды.
Для сложных задач по программированию ввели систему частичных баллов (как на олимпиадах по информатике) - даже если решение не идеально, модель получает feedback за пройденные тесты. А чтобы RL не застревал на простых примерах, добавили ресэмплинг: 10% данных брали из пула уже решенных задач, балансируя эффективность и стабильность обучения.
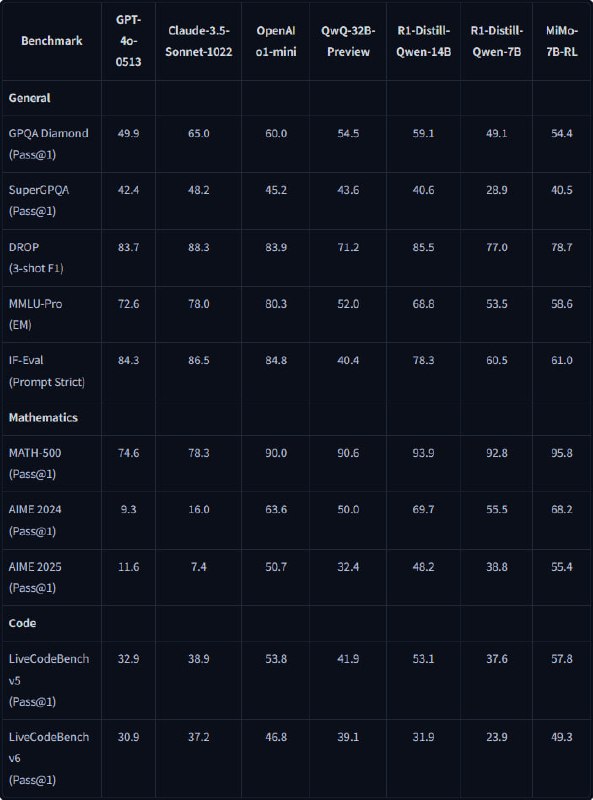
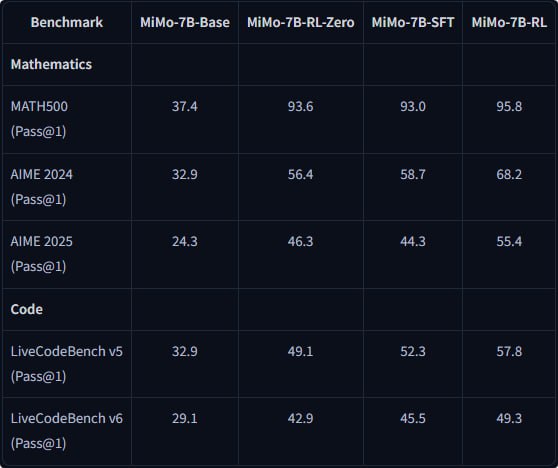
Результаты бенчмарков: на LiveCodeBench v6 MiMo-7B-RL набрала 49.3%, обойдя QwQ-32B на 10 пунктов, а на AIME 2025 — 55.4%, оставив позади OpenAI o1-mini. При этом базовая версия модели уже показывала 75.2% на BBH, что выше аналогов своего класса.
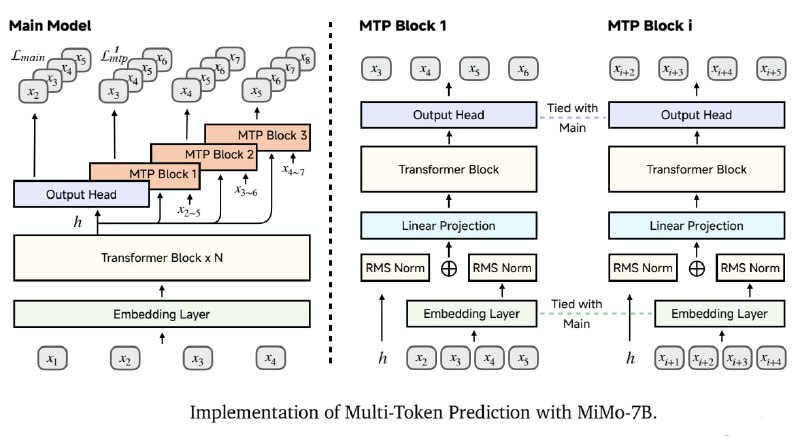
⚠️ Разработчики рекомендуют использовать для локального инференса их форк vLLM , он поддерживает MTP (Multiple-Token Prediction), но и на HF Transformers инференс тоже работает.
@ai_machinelearning_big_data
#AI #ML #LLM #RL #Xiaomi #MiMo